
Vor einiger Zeit hat man mir mal gesagt, wenn es um Aufwandsschätzungen geht, schätze ich „konservativ“. Will heißen: Ich schätze übervorsichtig, also zu hoch. Ob das stimmt? Ich weiß es nicht. Ich hab die Kritik also erstmal angenommen und zum Anlass genommen, darüber mal genauer nachzudenken. Zumal ich mir das bei mir gut vorstellen kann. Darüber hinaus gab es in letzter Zeit noch ein paar andere Begebenheiten, die mich dazu bringen, mir mal Gedanken übers Schätzen zu machen. Das Nachdenken hat ne Zeit lang gedauert. Der Text liegt hier also schon ein paar Monate rum. Dafür ist er aber auch umso ausführlicher geworden.
Warum schätzen wir daneben?
Selbst unter perfekten Bedingungen werden wir niemals in der Lage sein, immer perfekte Voraussagen zu machen. Mal werden wir zu hoch schätzen und mal zu niedrig. Wir können annehmen, dass eine Schätzung normalverteilt ist. Je besser wir schätzen, desto enger, gestauchter wird die Kurve (niedrige Standardabweichung), je schlechter wir schätzen, desto breiter und gestreckter wird sie (hohe Standardabweichung). Neben der generellen Ungenauigkeit beim Schätzen kann es natürlich noch ein Bias geben: Ein Schätzer kann die Tendenz haben, zu hoch oder zu niedrig zu schätzen. Das kann ein psychologischer Effekt oder ein systematischer Fehler sein.
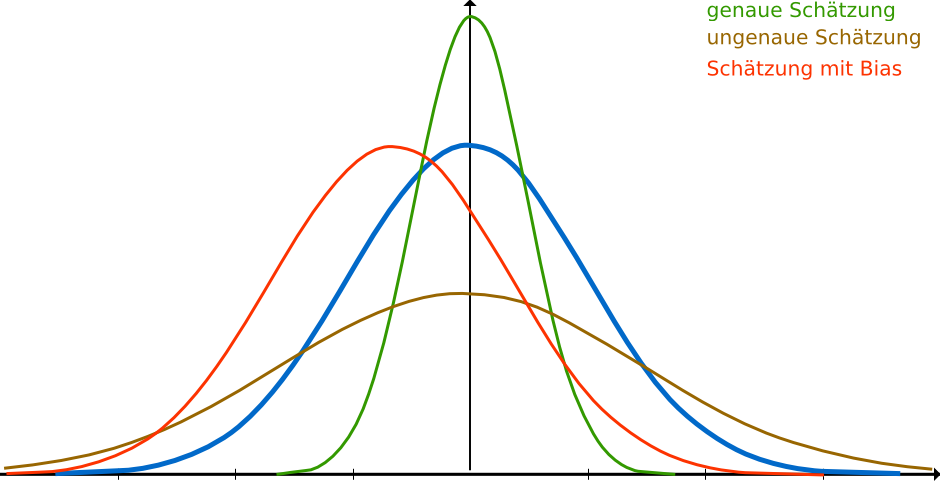
Das nächste Problem ist, dass das mit der Normalverteilung an sich schon gelogen ist. Typischerweise gibt es mehr Möglichkeiten, dass etwas schief gehen kann, als Möglichkeiten, dass alles perfekt klappt. Oder anders gesagt: Es kann immer noch katastrophaler werden, aber besser als in Windeseile bugfrei fertig sein ist nunmal nicht möglich. Eine gewisse Zeit braucht man auch zum einfach so runtercoden. Pessimistische Schätzungen sind demnach wahrscheinlicher als optimistische. Tom DeMarco veranschlagt deshalb für Aufwandsschätzungen eine asymmetrische Verteilung:

Weitere Fehler treten dadurch auf, dass manche Aufgaben und Anforderungen gar nicht geschätzt bzw. nicht berücksichtigt werden.
Unsere Probleme beim Schätzen sind also die folgenden:
- Standardabweichung
- Bias durch psychologische Effekte oder systematische Fehler
- Asymmetrische Wahrscheinlichkeitsverteilung
- Unberücksichtigte Aufwände
Wie können wir besser schätzen?
Die genannten vier Probleme mit der Schätzgenauigkeit können wir nun auf unterschiedliche Arten und Weisen angehen. Die wohl bekannteste Möglichkeit ist die Dreipunktschätzung. Statt nur einmal zu schätzen, schätzen wir einen optimistischen, einen pessimistischen und einen realistischen Fall und bilden ein gewichtetes Mittel. Der Hauptgrund für dieses Vorgehen ist die asymmetrische Wahrscheinlichkeitsverteilung. Angesichts derer erhalten wir mit der Dreipunktschätzung ein besseres Ergebnis als wenn wir nur den „realistischen“ (eher: wahrscheinlichsten) Fall genommen hätten. Ein weiterer Vorteil ist, dass hierdurch die generelle Unsicherheit der Schätzung transparent gemacht wird.
Gegen die anderen Probleme hilft die Dreipunktschätzung nicht. Was aber hilft, ist das Gesetz der großen Zahlen: Statt einer einzelnen Schätzung, schätzen mehrere Leute unabhängig voneinander. Wenn die Schätzungen stark differieren, wird darüber diskutiert, was ggf. unberücksichtigte Aufwände aufdeckt oder aber vermeintliche Aufwände als solche erkennbar macht. Ein Bias wird im besten Fall ausgeglichen (wenn die Schätzer in unterschiedliche Richtungen ausschlagen), in der Regel etwas gebessert, aber auch im schlechtesten Fall wird das Problem dadurch zumindest nicht größer. Der Hauptvorteil ist aber die verringerte Standardabweichung durch die Kombination mehrerer Schätzungen. Die Schätzung wird genauer.
Aufwandsschätzungen funktionieren in etwa so, dass man sich vorstellt, was man alles tun muss um eine Anforderung umzusetzen. Ich muss Code an diesen und jenen Stellen anpassen, die Schnittstellen mit diesen und jenen Leuten abstimmen, hier Tests schreiben und dort dokumentieren. Ich stelle mir vor, wie lange es dauert, das zu tun und komme so zu einer Schätzung.
Was ich mir in aller Regel nicht vorstelle, ist das, was dann aber doch tagtäglich passiert und maßgeblich unseren Entwickleralltag bestimmt: Mein Rechner sagt, ich muss neu booten, damit Updates eingespielt werden können. Es gibt einen aufwändigen Mergekonflikt in der Versionsverwaltung. Das Testsystem funktioniert gerade nicht. Anton muss heute früher gehen. Berta kommt nicht zum Programmieren, weil sie ungeplant den ganzen Tag in Meetings rumsitzt. Bugs werden gemeldet und müssen schnell analysiert und behoben werden. Der Tester hat ne Frage und Eclipse ist auch mal wieder abgestürzt. Das alles passiert. Manches davon ist normal, anderes sollte nicht sein, ist aber so. Manches kommt regelmäßig, anderes ungeplant und gehäuft genau dann, wenn man nicht damit rechnet. Trotzdem ist das Alltag. Aber ich stelle es mir nicht vor, wenn ich schätze. So etwas ist verdammt schwer gedanklich in die Aufwandsschätzung mit einzubeziehen.
Auch Refactoring ist so ein Punkt. Manche Refactorings gehören ganz klar zu einer Story. Andere Refactorings lassen sich vielleicht eins oder zwei Stories aufschieben. Aber irgendwann fällt der Aufwand an; entweder bei der einen oder der anderen Story. Auch das verzerrt natürlich die Schätzungen und eigentlich müsste ich das anteilig auf alle Stories draufrechnen. Tue ich aber in aller Regel nicht, weil ich nur schwer raten kann, wie viel das letztendlich ist.
Kurz gesagt: Es ist leicht, sich vorzustellen, wie lange man im Optimalfall für eine Entwicklungsaufgabe benötigt. Realistische Schätzungen sind weitaus schwerer. Das einzige, was wir tun können, ist nach Gefühl einen gewissen Prozentsatz an Unsicherheit und Puffer für mögliche Probleme auf zu addieren. Und auch das klappt nur bedingt gut. Douglas Hofstadter hat das mal so formuliert:
„Hofstadter’s law: It always takes longer than you expect, even when you take into account Hofstadter’s Law.“
Insgesamt unterliegen Schätzungen diversen psychologischen Verzerrungseffekten. Die Kognitionspsychologie hat diese untersucht und beschrieben. Das oben ausgeführte Problem, dass wir die Zeit, die wir für eine Tätigkeit brauchen, tendenziell unterschätzen, weil wir uns eher den Optimalfall vorstellen, als die Realität, hat dabei sogar einen eigenen Namen erhalten: Planning Fallacy oder zu Deutsch: Planungsfehlschluss.
Aufwand selbst ist also schwer zu schätzen. Zum Glück gibt es einen Trick mit dem man sich um dieses Problem elegant herum retten kann: Man schätzt den Aufwand gar nicht direkt, sondern man schätzt Komplexität. Diese kann man hinterher wieder auf Aufwände und Zeiten mappen. In der agilen Softwareentwicklung verwendet man hierfür Storypoints, die ein abstraktes Maß an Komplexität darstellen. Die Umrechnung von Storypoints in Zeit geschieht dann auf Basis echter Erfahrungswerte. In der Vergangenheit haben wir durchschnittlich X Storypoints in einem Sprint geschafft. Es ist anzunehmen, dass das in Zukunft auch so ist. Dadurch, dass wir Vergleichswerte aus der Vergangenheit heranziehen und nicht bloß nach Gefühl schätzen, vermeiden wir einen Teil der oben erwähnten psychologischen Verzerrungseffekte. Wenn unsere Schätzung zu dem passt, was wir tatsächlich in der Vergangenheit zu leisten im Stande waren, kann sie schonmal nicht total verkehrt sein.
Wir schätzen also Komplexität. Was aber ist das? Kurz gesagt: Alles was mehr ist, macht etwas komplexer. Mehr Code zu schreiben, viele verschiedene Stellen im Code zu ändern, viele Leute mit denen man sich abzustimmen hat, viele Dinge, die man gleichzeitig bedenken muss, viele Sonderfälle, die zu beachten sind, viele Dinge, die alle noch irgendwie nebenher zu tun sind und die man nicht einfach abhaken kann, … Alles das macht eine Aufgabe komplexer. Und das ist leichter zu schätzen als Aufwand, denn im Grunde genommen muss man „nur“ zählen.
Genau genommen machen wir hier aber etwas Merkwürdiges. Wir schätzen eine Größe (Komplexität) und wollen damit eine Aussage über eine andere Größe (Aufwand) treffen. Das funktioniert, weil es eine gewisse Korrelation zwischen Komplexität und Aufwand gibt. Eine statistische Korrelation. Das ist in etwa so, wie wenn wir an eine Grundschule gehen, dort ein Kind sehen und herausfinden wollen, ob es in die erste, zweite, dritte oder vierte Klasse geht.
Angenommen wir messen oder schätzen das Gewicht des Kindes. Das Gewicht ist natürlich nicht allein ausschlaggebend und schon gar nicht eindeutig für eine Schulklasse, aber es herrscht eine gewisse Korrelation. Ein Kind das 23kg wiegt ist vermutlich sieben Jahre alt und geht in die zweite Klasse. Vermutlich. Vielleicht auch erste oder dritte Klasse. Oder es ist sehr klein für sein Alter und geht doch schon in die vierte. Oder es hat ne Klasse übersprungen oder ist sitzen geblieben. So ganz sicher können wir uns also nicht sein, aber wenn wir uns entscheiden müssten, würden wir sagen, es geht in die zweite Klasse.
Viel besser wird die Schätzung, wenn wir nicht das Gewicht eines einzelnen Kindes, sondern das Gesamtgewicht aller 17 Schüler in der Klasse ermitteln. Insgesamt 426kg, ah, muss wohl doch ne dritte Klasse sein. Für ganze Schulklassen funktioniert das super, für einzelne Kinder nur so mäßig.
Und genauso ist es mit Storypoints. Eine Story mit einer Komplexität von 8 Punkten hat im Mittel einen gewissen Aufwand. So wie ein Kind, das 23kg wiegt, ein gewisses Alter hat. Und ja, wenn wir uns unbedingt festlegen müssen, kann man diese Komplexität von 8 SP in einen Aufwand in Personentagen umrechnen. In vielen Fällen funktioniert das. Aber es hat seine Grenzen. Die Idee hinter dem ganzen Kram mit den Storypoints ist es ja, die gesamten Storypoints in einem Sprint zu bewerten und darüber eine Aussage zu treffen. Und dafür funktioniert das auch ziemlich gut. Man sollte sich aber nicht wundern, wenn zwei Stories, die beide 8SP schwer sind, sich deutlich im Aufwand unterscheiden. Es wundert sich ja auch niemand darüber, dass Paul und Marie, die beide genau 23kg wiegen, in unterschiedliche Klassen gehen.
Storypoints sind merkwürdig und man kann das nun als total verquere Idee abtun. Wir messen bzw. schätzen etwas um eine Aussage über etwas ganz anders zu erhalten. Wenn man sich das aber genau betrachtet, muss man sagen: So ungewöhnlich ist das gar nicht. Eine Waage beispielsweise misst eine Länge (die Auslenkung einer Feder) um eine Aussage über eine Masse zu treffen. Das funktioniert in aller Regel ganz gut. Außer man benutzt die Waage im Gebirge, im Fahrstuhl oder auf dem Mond — oder die Feder ist ausgeleiert. Trotz dieser Probleme benutzen wir ständig Waagen.
Sie Sache hat also ihre Grenzen, aber im Großen und Ganzen sind Waagen schon eine tolle Sache — und Storypoints auch. Storypoints sind nämlich nicht nur vergleichsweise leicht zu ermitteln, sondern sie haben noch eine Reihe weiterer schöner Eigenschaften. Beispielsweise eliminieren sie das Problem mit dem Bias, weil sie einheitenlos sind. Storypoints sind charakteristisch für ein Team. Angenommen ein Team schätzt die Komplexität von Stories generell zu hoch ein. Dann wird dieses Team schlicht und einfach mehr Storypoints in einem Sprint schaffen. Wenn das Team aber weiß, wie viele Storypoints es in einem Sprint schafft, dann hat es nicht zu hoch geschätzt. Wenn man in Storypoints schätzt, kann man also prinzipbedingt gar nicht generell zu hoch oder generell zu niedrig schätzten. Man wird einfach einen anderen Umrechnungsfaktor von Storypoints in Zeit, also eine andere Velocity haben.
Ich hatte ja eingangs erzählt, dass man mir gesagt hat, ich schätze „konservativ“. Angesichts dieser Tatsache kann ich nur zu dem Schluss kommen: Wenn ich in Storypoints schätze, geht das gar nicht. Nun könnte es noch sein, dass ich bei den Schätzrunden tendenziell höher als meine Teamkollegen schätze (was aber wiederum nicht schlimm wäre, weil wir uns als Team eh auf eine Zahl einigen müssen und mein Bias dann in der Velocity mit eingepreist wäre). Oder die Aussage könnte sich auf die wenigen Male beziehen, wo ich in Personentage schätzen muss. Wobei ich dann eigentlich wieder der Planning Fallacy unterliegen müsste… Hm…
Die Sache mit der Genauigkeit
„Wie weit seid ihr?“
„Drei Meter, fünfeinhalb Kilo und zwei Äpfel.“
„In Prozent!“
„37,28%“
„Aha?!“
Nur weil man scheinbar genaue Zahlen nennen kann, heißt das natürlich nicht, dass die Genauigkeit, die diese Zahlen suggerieren, auch tatsächlich vorhanden ist. Es gibt Personenwaagen, die das Gewicht auf 100g genau anzeigen. Allerdings ist so ein Ding weder sonderlich genau geeicht, noch macht eine Gewichtsangabe in diesem Bereich überhaupt Sinn. Trinke ein Glas Wasser und du bist sofort 200g schwerer. Nicht, dass das die Waage zwangsweise mitkriegt — schon gar nicht, wenn man sie auf dem gefliesten Badezimmerboden um ein paar Zentimeter verrückt.
Deshalb verwendet man bei Schätzung in Storypoints i.d.R. nur Inkremente der Fibonacci-Folge: 1, 2, 3, 5, 8, 13, 21, etc. Kleine Stories kann man vergleichsweise genau schätzen — je größer die Story, desto größer die Ungenauigkeit. Zwischen 13 und 15 Storypoints besteht kein wirklicher Unterschied. Das Schätzverfahren macht das deutlich. Die selbe Ungenauigkeit gibt es auch bei Schätzungen in Personentagen. Leider ist es da unüblich, in Fibonacci-Inkrementen zu schätzen. Zwischen 13 und 15 PT besteht ja auch kein Unterschied.
Diese Ungenauigkeit lässt sich nur mit enormem Aufwand merklich verringern. Wenn ich wissen will, wie das Wetter morgen wird, kann ich in den meisten Fällen einfach behaupten, das Wetter wird morgen ähnlich wie heute. In aller Regel passt das ganz gut. Wenn ich wissen will, wie dick ich mich anziehen muss und ob ich ne Jacke brauche, reicht mir diese Genauigkeit vollkommen aus. Man kann natürlich genauer schätzen. Aber Anbetracht des enormen Aufwands, den die moderne Meteorologie betreibt, ist diese Wetterprognose nur geringfügig schlechter als das, was uns täglich im Fernsehen verkündet wird. Jegliche Aussage über das Wetter in 14 Tagen ist reine Spekulation — auch wenn man abartig viel Aufwand betreibt. In der agilen Softwareentwicklung sagt man deshalb: Ich gebe mich lieber mit Schätzungen der Qualität „Wetter von Gestern“ zufrieden und nutze die so freigewordene Zeit, schonmal um mit meiner Arbeit anzufangen. Egal wie viel Aufwand ich in die Schätzung stecke: Schneller macht mich das ja nicht.
Ähnliche Effekte treten auf, wenn der Projektmanager nach dem aktuellen Fortschritt im Sprint fragt. Prozentzahlen suggerieren eine Genauigkeit, die nicht da ist. Nicht umsonst spricht man in der Softwareentwicklung von der 90-90-Regel. Naja… zumindest gilt so etwas wie das Paretoprinzip: 80% Fortschritt erhält man bereits mit 20% des Aufwands. Eine Auskunft „wir sind zu 80% fertig“ ist also immer gefährlich. Das liegt daran, dass es die Rand-, Sonder- und Spezialfälle sind, die manche Dinge kompliziert machen. Außerdem bestehen die letzten 20% häufig in so Dingen wie Abstimmungen mit anderen, warten auf irgendwelche Freischaltungen und Testdaten und dem Integrationstesten und der damit verbundenen Erkenntnis „huch da ist ja doch was anders als gedacht“.
Die Frage „wie weit seid ihr?“ klingt oft wie das nervige „sind wir bald da?“ von kleinen Kindern im Auto. Und ich muss gestehen, dass ich manchmal auch ähnlich reagiert habe, wie Eltern, die diese Frage zum fünften Mal innerhalb von zehn Minuten hören. Die Frage wird aber wohl nicht einfach aus Jux und Dollerei gestellt. Lustigerweise sind die Beweggründe aber jeweils unterschiedlich und — zumindest für mich — nicht immer klar ersichtlich.
- Manchmal bedeutet die Frage „Welchen Fortschritt muss ich in die Präsentation für unsere Auftraggeber eintragen?“. — Wobei sich hier eigentlich die Frage nach der richtigen Granularität stellt. Interessiert die Auftraggeber wirklich der Fortschritt einer einzelnen Story? Oder nicht eher der Gesamtfortschritt der Entwicklung?
- Manchmal bedeutet die Frage „Passt noch alles oder muss ich irgendwie umplanen?“
- Manchmal auch „Können wir am Mittwoch eine neue Version in die QA geben?“
- Oder auch „Das andere Team wartet auf diese Story, können wir die hochpriorisieren?“
- …
Die Beweggründe sind ähnlich, aber im Detail doch anders und oft würde es helfen, diese zu kennen, um zu verstehen, was meine Antwort auf die Frage bedeuten würde. In Zukunft muss ich mir wohl vornehmen, hier extra nachzufragen, damit ich dann auch wirklich hilfreiche Antworten geben kann. Mit „80%“ ist ja keinem gedient.
Grob- und Langzeitschätzungen
Manchmal kommt man nicht umhin, mehr zu schätzen als in den nächsten eins, zwei Sprints gemacht werden soll. Grobschätzungen für zukünftige Aufgaben können durchaus sinnvoll sein. Allerdings ist so etwas natürlich besonders schwierig. Nicht umsonst legt man diversen berühmten Persönlichkeiten gerne den folgenden Satz in den Mund: „Prognosen sind schwierig, insbesondere wenn sie die Zukunft betreffen.“
Das größte Problem: Die Zukunft ist noch unbekannt. Man kann leicht irgendwelche Aufgaben vergessen zu schätzen. Typischerweise ändern sich über die Zeit auch die Anforderungen, zumindest aber verbessert sich das Verständnis der Anforderungen mit der Zeit. Auch Prioritäten können sich ändern, die Teamzusammensetzung oder technische und organisatorische Rahmenbedingungen.
Deshalb ist es wichtig, sich zu überlegen, wie man so eine Grobschätzung angeht. Möglicherweise sind zwar schon sehr viele Stories grob bekannt, mit ziemlicher Sicherheit fehlen da aber jeweils diverse Informationen. Gemeinerweise fehlen meist Informationen über Sonder- und Spezialfälle, über technische Unwägbarkeiten und organisatorische Hindernisse. Also über alles das, was die Komplexität maßgeblich beeinflusst. Man könnte jetzt also alle zukünftigen Stories auf Basis der momentanen Informationslage schätzen. Weil das sehr aufwändig ist, macht man das nicht im gesamten Team, sondern teilt die Stories im Team auf, sodass jede Story nur einmal geschätzt wird. Folge: Es gibt bei der Schätzung nicht nur eine große Unsicherheit (hohe Standardabweichung), sondern auch eine Tendenz, zu niedrig zu schätzen, weil diverse Komplexitätstreiber noch gar nicht bekannt sind.
Softwareentwicklung ist hier wie Schach spielen. Es ist nicht sonderlich sinnvoll, alles im Detail bis zum Ende durchplanen zu wollen. „In 43 Zügen schlag ich dich schachmatt — mit meinem Läufer — von H3 auf C8.“ Trotzdem kann man natürlich auch ein Schachspiel grob in Phasen unterteilen: Zuerst rücke ich vor, mach dann eine Rochade, bringe meinen König in Sicherheit und greife dann von der Seite aus an (So irgendwie. Ich kann nur unzureichend Schach spielen). Eine Grobschätzung muss vor allem eins sein: grob. Je weniger Informationen man hat, desto gröber müssen die zu schätzenden Arbeitspakete und desto gröber die Einheiten sein. Besser also man schätzt nicht auf Storyebene. Aber man kann mehrere Stories zu größeren Paketen schnüren und diese gemeinsam schätzen. Und man schätzt besser nicht in Storypoints und schon gar nicht in Personentagen, sondern vielleicht in Sprints oder Team-Wochen. Gröber eben.
Vermutlich ist es auch hilfreich, vergangene Stories ebenfalls in solche größeren Pakete zu gruppieren und dann die neuen Pakete damit vergleichen. Ganz ähnlich wie Storypoints… dann eben Packagepoints oder was auch immer. Ziel muss es jedenfalls sein, der mangelnden Informationslage irgendwie Herr zu werden und es zu vermeiden, Komplexitäten zu vernachlässigen, weil man sie noch nicht kennt. Sollte irgendwann mal wieder eine Grobschätzung anstehen, will ich das zumindest mal vorschlagen.
Einzelschätzungen
Ein weiteres Szenario, das manchmal vorkommt, ist, dass um eine Schätzung für eine einzelne Story gebeten wird. Diese Schätzung soll dann aber nicht nur für die Sprintplanung verwendet werden, sondern auch nach außen kommuniziert werden. Mit den bisher beschriebenen Methoden befinden wir uns hier allerdings in einem Dilemma. Schätzen wir in Storypoints, dann sind wir für eine einzelne Story recht ungenau. So, wie wenn wir die Klassenstufe eines einzelnen Schülers über dessen Gewicht bestimmen wollen. Storypoints sind für Einzelschätzungen eigentlich nicht gedacht. Schätzen wir aber wieder in Personentagen, so handeln wir uns wieder die ganzen Probleme wie die Planning Fallacy ein.
So eine richtig tolle Lösung für dieses Problem hab ich momentan nicht parat. Das einzige, was mir einfällt, ist beide Schätzverfahren anzuwenden und dann darüber einen Mittelwert zu bilden. Ob das klappt? Ich weiß es nicht. Aber auch das werde ich einfach mal vorschlagen. Wir müssten hinterher nur gucken, dass wir im Nachhinein die Schätzung nochmal mit dem tatsächlichen Aufwand vergleichen. Das bedeutet auf der Granularitätsebene natürlich auch wieder Arbeit, die sich nur im Einzelfall lohnt.
Ein Effekt, den ich bei Einzelschätzungen immer wieder beobachte, ist folgender: Eine Einzelschätzung wird in Storypoints angegeben und in Personentagen umgerechnet. Das Ergebnis erscheint den Projektbeteiligten zu hoch zu sein. Das kann zutreffend sein, muss aber nicht. Eine kurze Diskussion zwischen Anforderern und Entwicklern soll das klären.
Entscheidend ist jetzt, ob die Diskussion Aufwände bzw. Personentage oder Komplexität bzw. Storypoints als Grundlage nimmt. Sehen wir uns mal einen typischen Verlauf einer solchen Diskussion in beiden Fällen an:
Fall A: Aufwände dienen als Diskussionsgrundlage
Anforderer: „Eure Schätzung erscheint mir zu hoch. Das entspricht fast drei Wochen Aufwand!“
Die Entwickler können nicht leugnen, dass das viel klingt. Möglicherweise geben die Entwickler einfach nach. Vielleicht aber folgt sowas:
Entwickler: „Storypoints kann man nicht in Zeit umrechnen.“
Anforderer: „Ach Quatsch! Das machen wir doch jeden Tag. Deshalb schätzen wir doch.“
Gewissermaßen haben beide Seiten recht. Aber der Unterschied ist einfach zu vermitteln und die Situation noch schwerer zu klären. Vielleicht sagt jetzt der Entwickler nun folgendes:
Entwickler: „Naja, wir haben ja auch Overhead. Wir müssen Fragen der Kollegen beantworten, den Rechner neu starten, Emails beantworten, Bugs fixen…“
Anforderer: „Aber das gehört doch gar nicht hier dazu. Das sollt ihr doch gar nicht da mit reinschätzen!“
Und wieder haben Entwickler und Anforderer erfolgreich aneinander vorbei geredet. Klar, wird das nicht mit in die Komplexität mit eingerechnet. Aber der Umrechnungsfaktor, der sich aus geschafften Storypoints pro Sprint ermittelt, berücksichtigt all das. Wie oben erklärt, ist das gerade der Grund für die Verwendung von Storypoints. Diese zusätzlichen Aufgaben sind schwer zu beziffern und werden deshalb nur indirekt mit eingerechnet.
Fakt ist jedenfalls: Die Reaktionen von beiden Seiten sind vollkommen verständlich, aber sie führen nicht zum Ziel. Die eigentliche Frage, ob die Schätzung nun zu hoch ist oder nicht, wurde bisher nämlich immer noch nicht angegangen. Ich halte diesen Weg also für kontraproduktiv.
Fall B: Die Komplexität dient als Diskussionsgrundlage
Mögliche Argumente der Anforderer können hier folgende sein:
- Ist diese Story wirklich aufwändiger als diese andere, die ihr geringer geschätzt habt?
- Reicht es nicht, wenn ihr bei X und Y Anpassungen vornehmt, aber Z unangetastet lasst?
- Gibt es hier wirklich so viele Sonderfälle?
- …
Es gibt hier sogar eine ganz zentrale Frage, die die Entwickler unter Zugzwang setzen kann, die Anforderer hier stellen können um wirklich weiter zu kommen: „Was macht das hier so komplex?“ Sobald diese Frage gestellt ist, müssen nämlich Fakten auf den Tisch. Es wird über die Sache diskutiert und nicht mehr über die Schätzung an sich. „Ich schätze 15 PT“ ist eine Behauptung. „Wir müssen X und Y anpassen“ ist eine nachprüfbare oder zumindest diskutable Aussage.
So ganz ohne Probleme ist dieser Weg aber natürlich auch nicht. Es besteht die Gefahr, dass der Eindruck entsteht, die Komplexität wäre der einzige Aufwandstreiber bzw. die direkte Ursache für den Aufwand.
So gesehen ist es nicht immer hilfreich, zu argumentieren, dass ein gewisser Komplexitätstreiber keine hohen Aufwände produziert. Beispielsweise erhöht die Anzahl der Personen, mit denen man sich abstimmen muss, die Komplexität. Je mehr Leute desto komplexer. Folgendes kann aber passieren:
Anforderer: „Was ist denn da so komplex?“
Entwickler: „Wir müssen uns beispielsweise mit Team B abstimmen.“
Anforderer: „Das ist doch nicht kompliziert! Das ist nur eine Mail. Das geht schnell.“
Auch wenn es hier vordergründig um Komplexität geht, wird eigentlich der Aufwand betrachtet. „Das geht schnell.“ deutet schon darauf hin. Richtiger müsste der Anforderer also sagen „Das ist doch nicht aufwändig! Das ist nur eine Mail. Das geht schnell.“ Womit wir wieder bei Fall A. wären. Wenn es schlecht läuft, folgt jetzt sowas:
Entwickler: „Ja, das geht schnell, aber wir müssen das im Kopf behalten. Wir können das nicht einfach abhaken und gut ist. Zuerst müssen wir dran denken, dass wir die Mail zu schreiben haben, dann müssen wir im Kopf behalten, dass wir noch auf ne Antwort warten, ggf. nachhaken, wenn keine kommt, etc. Abstimmung bedeutet Komplexität. Gerade für Entwickler ist es kompliziert, viele Dinge auf einmal im Kopf behalten zu müssen. Wir können uns besser auf eine Sache konzentrieren.“
Anforderer: „Wenn das für euch so kompliziert ist, dann nehm ich euch die Arbeit einfach ab. Ich schreib die Mail für euch und ihr könnt euch konzentrieren.“
Entwickler: „Das hilft nicht. Wir müssen dann doch trotzdem…“
Und wieder reden Entwickler und Anforderer aneinander vorbei und diskutieren um alles nur nicht um das, worum das es eigentlich geht: Ist die Schätzung nun zu hoch oder nicht? Unbemerkt von beiden Seiten ist die Diskussion wieder abgedriftet weg von Komplexität hin zu Aufwand. Und wir wissen ja schon, dass Aufwand direkt schätzen schwierig ist.
Obwohl diese Gefahr also besteht, denke ich, dass eine Diskussion um Komplexität zielführender ist, als eine Diskussion um Aufwand direkt. Das Schwierige ist, allen Diskussionsbeteiligen diese Problematik bewusst werden zu lassen.
Fazit
Schätzen ist schwer und man kann daran immer etwas verbessern. Ich glaube, das Wichtigste an der ganzen Sache ist zum einen, sich darüber mal detailliert Gedanken zu machen (das habe ich hier versucht) und zum anderen, im Team ein gemeinsames Verständnis der Problematik zu etablieren. Wie letzteres funktionieren kann, weiß ich noch nicht. Letztendlich wird das aber entscheidend sein, ob Schätzen weiterhin so anstrengend ist oder ob sich das generell bessern kann. Alles andere ist Kleinkram.
Im Großen und Ganzen bin ich aber davon überzeugt: Agil Software entwickeln heißt weniger genau schätzen und planen und dafür früher ankommen. Aber das ist eine weitere Einstellung, die es schwer hat, sich zu verbreiten…