
„Christian, we want you for president!“ Steffi, die Abteilungsleiterin der Betriebs-Kollegen steht in der Tür und bedeutet mir mitzukommen. So bin ich auch noch nicht begrüßt worden, denke ich mir und schaue wohl ziemlich verdutzt aus der Wäsche. Nachdem ich wieder in die Realität zurück gefunden habe, gehe ich mit ihr mit und befinde mich kurze Zeit später in einem kleinen Büro, in dem sich mehrere Manager um einen kleinen runden Tisch versammelt haben. „Christian, du musst uns was erklären.“
Diese Situation ist jetzt vielleicht drei oder vier Jahre her. Letztens hab ich mich daran erinnert und dachte mir, ich könnte etwas über Timeouts erzählen. Aber fangen wir von vorne an. Alles begann mit einem Incident. Einer unserer Services hatte gerade Verfügbarkeitsprobleme. Die Antwortzeiten waren miserabel und auch ein Neustart half nur kurz, das Problem in den Griff zu bekommen. Zusammen mit den Kollegen vom Betrieb haben wir das Problem untersucht. Auslöser war ein anderer Service, der sehr langsam, wenn überhaupt, antwortete.
Auf einem Application Server werden Threads typischerweise in einem ThreadPool vorgehalten. Jedes Mal, wenn ein RemoteCall gemacht wird, wartet der Thread auf die Antwort und ist so lange blockiert. Das ist erstmal ganz normales Verhalten. Wenn die Antwortzeiten aber hoch gehen, bedeutet das, dass die Threads lange blockiert werden. In der Zwischenzeit erhielt unser Service natürlich weiterhin Calls und so waren immer mehr Threads blockiert bis irgendwann der ThreadPool voll lief. Das führte dann dazu, dass unser Service komplett nicht mehr bzw. nur sehr langsam reagierte. Auch die Operationen unseres Services, die gar nicht zu Calls auf den ursächlich langsamen Service führten, waren auf einmal langsam, weil immer auf einen freien Thread aus dem Pool gewartet werden musste.
Es war schnell klar, dass das Anheben der Timeouts nicht sinnvoll war und so konzentrierten wir uns darauf, die Ursache zu beheben. Wir riefen den Betrieb des anderen Dienstes an und unterstützten ihn dabei, deren Problem zu beheben, sodass unser Service wieder funktionierte. Und das war der Augenblick als Steffi ins Büro kam. „Christian, we want you for president!“ Kurze Zeit später fand ich mich, wie schon erzählt, in einem Raum mit mehreren Managern wieder. Die Kollegen hatten gehört, dass ich davon abgeraten hatte, die Timeouts hoch zu setzen und wollten nun wissen, warum. Das schien doch eigentlich eine sinnvolle Vorgehensweise zu sein?!
Also erklärte ich den Kollegen das Problem: Das mit den ThreadPools hab ich ja schon beschrieben. Wenn wir jetzt die Timeouts hoch gesetzt hätten, würde das bedeuten, dass zwar etwas länger die Chance auf eine Antwort besteht, allerdings würden die Threads dadurch ja noch länger blockiert werden und der ThreadPool würde noch schneller voll laufen. Die Timeouts hoch zu setzen, würde das Problem also noch verschlimmern. Wir hätten die Timeouts also höchstens verkürzen müssen. Das kann sinnvoll sein, führt dann aber dazu, dass die User noch schneller eine Fehlermeldung sehen, auch, wenn vielleicht kurze Zeit später die Antwort da gewesen wäre.
Sinnvolle Timeouts
Man muss sich also sicher stellen, dass man sinnvolle Timeouts gesetzt hat. Aber was ist denn eigentlich ein sinnvoller Wert für einen Timeout? Ich höre immer wieder folgende Idee: Wir messen, wie lange ein Dienst normalerweise antwortet, packen dann da einen gewissen Puffer drauf (50%, 100%, 200%, was auch immer) und das wird dann unser Timeout. Auch das ist ein Vorgehen, das erstmal sehr sinnvoll klingt, aber genauer betrachtet genauso wenig sinnvoll ist, wie im Falle eines Incidents, Timeouts zu erhöhen. Ein Timeout definiert sich nämlich nicht aus der gewöhnlichen Antwortzeit, sondern aus der Zeit, die ich gewillt bin, zu warten — und zwar im schlimmsten Fall. So ist es auch irrelevant, wie lange ich denn normalerweise warten würde oder welche Antwortzeit ich mir wünsche. Timeouts definieren kein SLA. Wenn es ein SLA gibt, ist die dort definierte Reaktionszeit i.d.R. deutlich geringer als der Timeout.
Timeouts sind nicht für den Normalfall gemacht, sondern greifen im Ausnahmefall. Wir stellen uns vor, die Hütte brennt, überall qualmen die Server in den Rechenzentren und mein System so quälend langsam, dass es die Bits einzeln durch die Netzwerkkabel prügelt: Wie lange wartet der User, bevor er entnervt aufgibt? Das ist der Timeout. Angenommen mein System ist eine Website und der User hat das Browserfenster bereits zu gemacht und sucht stattdessen lieber niedliche Katzenbilder. Dann bringt es auch nichts, wenn ich kurze Zeit später die tollste Website der Welt präsentieren kann. Der User wird sie nie zu Gesicht bekommen, weil das Browserfenster ja schon zu ist. Ein Timeout bricht die Aktion ab und macht Ressourcen frei, damit der nächste User wieder etwas sieht, bevor er das Browserfenster zu macht.
Wie lange wartet nun so ein User typischerweise? Das ist gar nicht so einfach zu sagen. Kommt auf den Kontext an. Ein paar Daumenregeln:
- Alles kleiner 0,1s wird vom User als instantan wahrgenommen. Der User hat das Gefühl nicht warten zu müssen und quasi direkt auf den Daten zu arbeiten.
- Zwischen 0,1s und 1s bemerkt der User einen Delay, hat also nicht mehr das Gefühl, die Daten selbst an zu fassen, aber er wird noch nicht in seinem Gedankengang durch Warten unterbrochen.
- Alles ab 1s empfindet man als warten. Man wird im Gedankengang unterbrochen und wird unproduktiv.
- Ab 10s würde man eigentlich gerne etwas anderes machen und die Wahrscheinlichkeit, dass man das dann auch tut, ist schon recht hoch.
- Untersuchungen zeigen eine maximal tolerierbare Wartezeit von 15–20s (einige wenige sprechen von gut 40s).
- Wenn man häufig warten muss, nimmt die Geduld der User ab. Schon bei der zweiten langsamen Aktion ist die tolerierte Wartezeit deutlich geringer.
- Wenn der User eine Reaktion sieht (Seite baut sich langsam auf, ein Ladebalken erscheint, ein Spinner zeigt Aktivität an, etc.), steigt die Wartebereitschaft.
- Darüber hinaus gibt es noch diverse Faktoren, die einen Einfluss haben können: Art der Aufgabe bzw. der Aktion, Anspruch der User, Art des Warteindikators, etc.
(Weitere Infos zu tolerierbarer Wartezeit aus wissenschaftlicher Perspektive und aus SEO und Usability-Perspektive)
Ein sinnvoller Timeout für eine Webanwendung liegt also i.d.R. zwischen 10 und 20 Sekunden. Ein langer Timeout führt dazu, dass geduldige User die Anwendung noch bedienen können, führt aber zu einer höheren Ressourcenauslastung (inklusive dem oben beschriebenen Threading-Problem) und damit zu einer schlechteren Gesamtperformance. Ein niedriger Timeout bedeutet, dass sich die Anwendung insgesamt etwas schneller anfühlt und sparsamer mit Ressourcen umgeht, allerdings passiert es schneller, dass das System eben genau in diesen Timeout reinläuft, was zur Folge hat, dass auch User, die geduldig genug wären, etwas länger zu warten, nun eine Fehlermeldung statt ihrer Daten sehen. Für ein System, das auf ausreichend proportionierter Handware läuft, wird man Timeouts wählen, die sich am Nutzerverhalten orientieren. Systeme die für den Lastfall(!) unterdimensioniert sind, brauchen geringere Timeouts.
Ein weiterer Aspekt tritt auf, wenn die Antwortzeit von den Eingabedaten abhängt. Manche User werden nur wenige Daten bearbeiten und in einem solchen Fall ist die Anwendung i.d.R. auch performant. Einige wenige User wollen aber deutlich mehr Daten verarbeiten. Das sind dann diejenige Art von Power-Usern, die zwar das System auslasten, aber womöglich auch die besten und wichtigsten Kunden sind. Mal davon abgesehen, dass man für solche Power-User ggf. die Performance des Systems optimieren sollte, sind Timeouts hier eine entscheidende Größe. Ein zu kurzer Timeout bedeutet nämlich, dass für den gut zahlenden Power-User das System nicht nur langsam ist, sondern unbenutzbar, weil der User immer in den Timeout läuft und dadurch die Daten nicht vollständig verarbeitet werden können.
Was ist aber nun mit Systemen die keine direkte Nutzerinteraktion haben? Auch hier definiert sich der Timeout prinzipiell danach, wie lange ich gewillt bin, auf das Ergebnis der Operation zu warten. Vielleicht gibt es einen indirekten Nutzer, d.h. mein System hat zwar keine GUI, aber mein Client hat eine. Dieser Client wird einen Timeout setzen und es ist i.d.R. nicht hilfreich, die eigenen Timeouts länger zu wählen, als der Client. Ob der User nun das Browserfenster schließt oder der Client die Netzwerkverbidnung: Der Effekt ist derselbe. Womöglich gibt es auch fachliche Gründe für einen Timeout. Mein Regelkreis funktioniert nicht mehr, wenn ich zu lange auf den Sensorwert warte, das Auto hat längst einen Unfall gebaut, die Haltestelle, an der ich hätte aussteigen müssen, ist vorbei und die nützliche Info zum Bild aus dem Livestream interessiert niemanden mehr, weil jetzt etwas anderes zu sehen ist.
Deadline Propagation
In einer Microservice-Landschaft entstehen häufig Aufrufketten über mehrere Systeme. System A fragt B, B leitet weiter zu C, etc. Zu allererst ist es mal keine gute Idee, diese Ketten wuchern zu lassen, bis sie ins unendliche wachsen. Man sollte sich gut überlegen, welche Services, welche anderen aufrufen sollten bzw. wie man Services in Schichten und ähnlichen Strukturen organisiert. Bis zu einem gewissen Grad werden diese Aufrufketten aber vorhanden sein und das hat wiederum Auswirkungen auf Timeouts.
Angenommen wir haben folgende Aufrufstruktur:
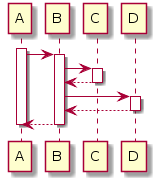
Das Offensichtlichste ist, dass B nicht länger auf C warten sollte als A auf B. Das zweite ist die Abhängigkeit von Timeouts. Angenommen C ist langsam und antwortet rechtzeitig, aber spät, wie lange darf ich dann noch auf D warten? Der heilige Gral der Timeouts ist deshalb ein Pattern namens Deadline Propagation: bei jedem Service-Aufruf wird mitgegeben, wie lange auf die Antwort gewartet wird. A sagt ruft also B auf und gibt bereits mit, dass auf die Antwort maximal 10 Sekunden gewartet wird. B gibt die 10 Sekunden weiter an C. C antwortet nach 8 Sekunden. Damit bleiben noch 2 Sekunden für D übrig. D erhält die 2 Sekunden als Deadline, weiß, dass das unrealistisch ist und gibt stattdessen eine Default-Antwort zurück — gerade noch rechtzeitig, damit die Antwort von B innerhalb der 10 Sekunden bei A ankommt.
Deadline Propagation ist Teil von gRPC einem Protokoll von Google für, sagen wir, Spezialfälle. Prinzipiell spricht aber nichts dagegen, das Pattern auch in normalen REST-Services einzusetzen.
Im Detail ist das natürlich noch ein bisschen komplizierter als hier dargestellt. Es gibt eine gewisse Latenz zwischen dem Abschicken und dem Empfangen der Nachricht beim aufgerufenen Service. Hier muss also jeweils ein Puffer eingerechnet werden. Oder aber man arbeitet mit Zeitstempeln als Deadline. Dann aber müssen die Uhren gut synchronisiert sein. Das sollte dank NTP zwar theoretisch machbar sein. Wenn die Uhren aber ausnahmsweise mal nicht synchron laufen, passieren ganz lustige Dinge, die man sich nicht unbedingt wünscht. Zeit ist kompliziert. Sollte ich jemals Deadline Propagation einsetzen bzw. implementieren, würde ich vermutlich eher mit Puffern statt mit festen Timestamps arbeiten.
Arten von Timeouts
Wir wissen jetzt also, dass wir unsere Timeouts sinnvoll dimensionieren müssen und dass sich der Timeout nicht aus dem gewöhnlichen Antwortverhalten, sondern aus meiner Wartebereitschaft ermittelt. Wir müssen diese Timeouts jetzt aber noch konfigurieren und werden sofort damit konfrontiert, dass es nicht nur einen Timeout gibt, sondern mehrere. Prinzipiell kann es bei jeder (Teil-)Operation, bei der ein Thread blockiert, einen separaten Timeout geben. Im Großen und Ganzen unterscheiden wir aber drei typische Arten von Timeouts: Connect Timeout, Socket Timeout und Pool Timeout (plus diverse Sonder-Timeouts auf die ich hier nicht eingehe).
Der Socket Timeout ist der Timeout, über den wir hier quasi die ganze Zeit reden. Angenommen ich habe eine Verbindung zu einem externen System (via Socket) und hab eine Anfrage gestellt. Wie lange warte ich auf eine Antwort? Zu beachten ist, dass das kein Harter Timeout für die gesamte Antwort ist. Der Socket Timeout definiert nur, wie lange ich auf das erste Byte der Antwort warte. Eine lange Antwort (beispielsweise ein großer Download) führt nicht zu einem Socket Timeout.
Der Connect Timeout ist die Zeit, die ich darauf warte, dass eine TCP-Verbindung aufgebaut wird. Mein System schickt ein SYN-Paket, die Gegenstelle antwortet mit SYN-ACK. Wie lange warte ich auf diese Antwort? Natürlich warte ich hier maximal die 10 Sekunden oder wie lange auch immer ich warten will. Aber in diesem speziellen Fall sollten wir noch eine weitere Überlegung anstellen. Warum antwortet die Gegenstelle nicht mit einem SYN-ACK? Womöglich ist eine Firewall dazwischen, die dafür sorgt, dass die Pakete verloren gehen. Dann macht es keinen Sinn, sonderlich lange zu warten. Der zweite typische Grund für einen Connect Timeout ist, dass das aufgerufene System überlastet ist. Die maximale Anzahl an Verbindungen mit dem aufgerufenen System ist erreicht. Auch dann sollte man nicht zu lange warten, weil man damit das aufgerufene System nur noch mehr unter Last setzt. Ein kurzer Timeout hilft hier, dem System wieder auf die Beine zu kommen, weil sich die Requests nicht aufstauen.
Darüber hinaus gibt es noch Pool Timeouts, beispielsweise den Connection Request Timeout. Das ist die Zeit die ich warte, dass ich eine gepoolte Ressource (im konkreten Fall eine gepoolte TCP-Verbindung) erhalte. Wenn der anschlägt, bedeutet dass, dass nicht das aufgerufene System, sondern mein System gerade überlastet ist. Auch hier kann ein niedrigerer Timeout sinnvoll sein, damit sich Requests nicht aufhäufen und sich mein System somit schneller erholen kann.
Circuit Breaker, Bulkhead, Pools & Co
Wenn es um Resilienz in verteilten Systemen geht, gibt es ein Pattern, das immer relativ schnell auf dem Tisch ist: Circuit Breaker. Der Grund dafür ist vermutlich, dass Netflix mit Hystrix viel Werbung für das Pattern gemacht hat. Dabei sind Circuit Breaker gar nicht mal so wichtig bzw. es gibt deutlich Wichtigeres. Um zu erklären, warum dem so ist, was man sich (neben sinnvoll gewählten Timeouts) vorher noch angucken sollte und für was Circuit Breakers doch gut sind, muss ich aber wieder ein neues Fass aufmachen. Der Artikel ist schon lang genug. Das muss also erstmal warten. In einem zweiten Teil werde ich diese Aspekte dann auch noch beleuchten. Vorher muss ich mich aber mal damit beschäftigen, was ich als Präsident denn so zu tun hätte. So schwer kann das doch nicht sein. Vielleicht sollte ich mit einem Twitter-Account anfangen.
Permalink
Super erklärt; danke!
Vielleicht solltest Du auch noch auf asynchrone Verarbeitung eingehen.
Permalink
Danke. Freut mich.
Durch asynchrone Verarbeitung kann man Latenzen optimieren. Bezüglich Timeouts sehe ich aber keine signifikant anderen Aspekte. Typischerweise machst du IO asynchron. Ja, du kannst an asynchronen Calls nochmal einen separaten Timeout einstellen. Faktisch ist das aber wieder der selbe wie der Timeout, der bei der IO gemacht wird. Wobei. Wenn ich mir das richtig überlege, stimmt das nicht ganz. Genau genommen ist das ein Timeout über alles, also bis zum letzten Byte (statt bis zum ersten wie beim SocketTimeout). Das könnte ich tatsächlich noch ergänzen.
Fällt dir sonst noch was ein?