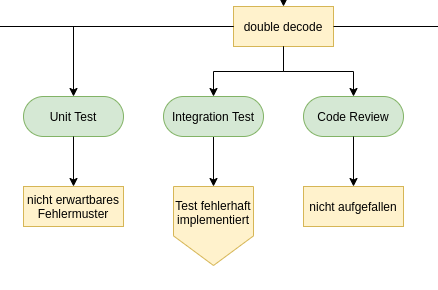
Der weise Tim und der Bug
Der weise Tim und die Schriftrolle Es begab sich zu der Zeit, als der weise Tim im Tal der großen Ringe weilte, das man das CERN nannte. Damals arbeitete er […]

Der weise Tim und die Schriftrolle Es begab sich zu der Zeit, als der weise Tim im Tal der großen Ringe weilte, das man das CERN nannte. Damals arbeitete er […]
„Es gibt die einen und die anderen, die Konkreten und die Abstrakten. Die Konkreten, das sind die, die sich im Code bewegen wie ein Fisch im Wasser. Sie kennen jedes […]
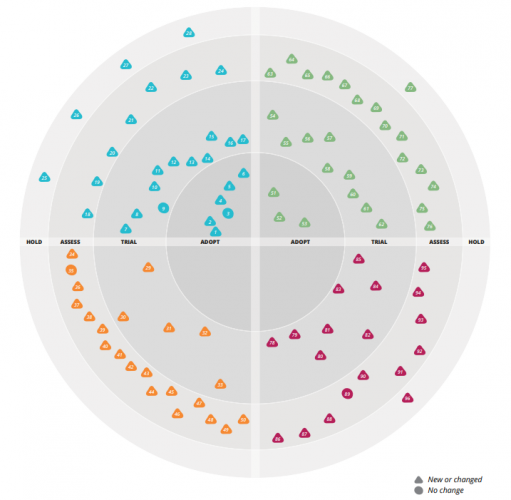
Joghurt und Anwendungen Meine Damen und Herren, der Joghurt ist abgelaufen! Es ist nicht zu leugnen. Wir müssen der Wahrheit ins Auge sehen und uns eingestehen, dass der Joghurt ein […]

Ich bin ständig am lernen und am besser werden. Und ehrlich gesagt hoffe ich, dass das auch nie aufhört. Mir ist es sehr wichtig, dass ich immer wieder an mir […]
Es gibt schönere Orte. Und doch standen sie alle in dieser staubigen Wüste und warteten. Dicke Regenwolken versperrten den Blick auf die Sterne. Blitze zuckten am Himmel. Eigentlich hätten sie […]
Die Antwort auf alle Fragen in der Softwareentwicklung ist „it depends“. Diese Weisheit ist hinlänglich bekannt, aber genauso bekannt ist, dass diese Antwort ziemlich langweilig ist. Viel interessanter ist die […]
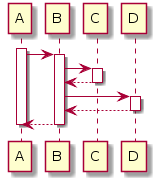
„Christian, we want you for president!“ Steffi, die Abteilungsleiterin der Betriebs-Kollegen steht in der Tür und bedeutet mir mitzukommen. So bin ich auch noch nicht begrüßt worden, denke ich mir […]

Letztens dachte ich noch, ich wüsste, was ein Kunde ist. „Das weiß doch jeder“, dachte ich. Und das obwohl ich es eigentlich besser hätte wissen müssen. „Ein Kunde ist jemand, […]
Leute, sortiert eure Spaghetti, sonst habt ihr ein Problem! Ich rede natürlich nicht davon, in der Kantine die Bolognese auseinander zu nehmen (ja, ganz sicher, selbst die größten Nerds unter […]
Damals in meinem Physik-Leistungskurs hatten wir die Tradition, Freitag morgens die Stunde mit einem Witz zu beginnen. Es musste aber natürlich ein Physiker- oder Mathematikerwitz sein. Manchmal hab ich einen […]