
Joghurt und Anwendungen
Meine Damen und Herren, der Joghurt ist abgelaufen! Es ist nicht zu leugnen. Wir müssen der Wahrheit ins Auge sehen und uns eingestehen, dass der Joghurt ein für alle Mal sein Mindesthaltbarkeitsdatum überschritten hat. Was, meine geschätzten Koll…Familienmitglieder gedenken wir jetzt zu tun?
Der Begriff „Lifecycle Management“ oder kurz LCM geniest nicht unbedingt den besten Ruf. Und ich kann es niemandem verdenken, der innerlich die Augen verdreht, wenn es um irgendwelche Elfenbeinturm-Gremien geht, die die Einsetzbarkeit von Technologien bewerten sollen. Mir geht es da kaum anders. Ich könnte ja selbst Käsfüße kriegen, wenn ich auch nur an so etwas denke. Und doch bin ich Teil genau eines solchen Gremiums. Dabei bin ich das noch nicht einmal gezwungenermaßen, sondern ich finde LCM im Grunde genommen gut. Aber wir unterziehen auch unsere Arbeit in diesem unserem Gremium dem Loriot-Test. Aber dazu später.
Wenn ich als einzelner kleiner Entwickler eine einzelne kleine Anwendung schreibe, ist die Welt noch einfach. Ich kann ganz einfach bestimmen, wann ich meine Anwendung schreibe, wann ich diese update und wann ich sie wieder los werde. So wie ich bei meinen zwei Joghurts im Kühlschrank auch ganz einfach darauf achten kann, dass ich sie esse, bevor sie ablaufen. [1]
Wenn man aber hunderte Joghurts hat oder hunderte Anwendungen mit Hunderten Libraries, dann lohnt es doch, mal kurz darüber nach zu denken, wie man das organisiert. Und wir alle kennen das doch: Im täglichen Projektgeschäft gehen wichtige, aber nicht dringende Tätigkeiten schnell unter: das Refactoring der Gottklasse, das Updaten der Library und das Migrieren auf die neue Plattform. Manches davon kriegen wir als professionelle Softwareentwickler noch ganz gut gestemmt. Wer genug von Bob Martin gelesen hat, weiß, wie man die Pfadfinderregel anwendet. Aber was ist mit Anwendungen, die man seit zwei Jahren nicht angefasst hat (weil es dazu keine Projekte gab)? Und was ist mit größeren Plattform-Updates, die man nicht so einfach nebenher macht? Wir sind schnell dabei, auf das Management zu schimpfen und zu beklagen, dass man für wichtige Wartungsaufgaben keine Zeit kriegt, weil neue Features irgendwie immer wichtiger oder zumindest dringender sind.
Aber das Ganze hat natürlich Konsequenzen. Für einige Zeit geht das gut. Irgendwann aber haben sich die Probleme und Aufgaben zu einem gewaltigen Berg aufgestaut. Wir wissen, dass man besser häufiger kleinere Änderungen macht als eine große. Wir wollen also unbedingt vermeiden, dass 50 Joghurts auf einmal ablaufen und ein paar Wochen später alle schimmelig werden. Wir wollen unbedingt vermeiden, dass 50 Anwendungen alle irgendwie gleichzeitig auf die neue Plattform gehoben werden müssen. Wenn das doch das Management verstehen würde! Ja, wenn…
Aber vielleicht würde das Management das ja verstehen, wenn wir es nur schaffen, das richtig zu kommunizieren. Und da kommt nun LCM ins Spiel. LCM ist der Versuch, das, was wir Entwickler irgendwie die ganze Zeit einfordern, in die Sprache des Managements zu übersetzen. Wir wollen das Upgrade nicht einfach nur machen, weil neue Technologie cool ist. Wir wollen es machen, weil es wirtschaftlich geboten ist, weil es Schaden vom Unternehmen abhält und neue Chancen bietet.
Vom Produktlebenszyklus zum Anwendungslebenszyklus
Habt ihr noch Disketten zu Hause? Ja, diese Dinger, die aussehen, als hätte jemand das Save-Icon einem 3D-Drucker zum Fressen gegeben. Ich hab noch einen 10er-Pack. Unbenutzt und originalverpackt. Noch eingeschweißt! Vor 20 Jahren hab ich sowas noch benutzt. Jetzt weiß ich nicht mehr, was ich damit anfangen soll außer für 30€ bei ebay verkaufen. Ich hab hier auch noch eine Spindel CD-Rohlinge rumliegen. Und irgendwo müsste ich noch eine CD-RW haben.
Produkte unterliegen einem gewissen Lebenszyklus. Sie werden ersonnen, entwickelt, auf den Markt gebracht, vergrößern ihren Marktanteil, erreichen einen Höhepunkt und nach einer gewissen Phase des Niedergangs verschwinden sie wieder. Wäre ich jetzt BWLer, könnte ich bestimmt ganz toll darüber referieren, wie man sich in den einzelnen Phasen zu verhalten hat, wie man mit einem Relaunch den Niedergang eines Produkts ggf. aufhalten kann und was das alles für den Gewinn bedeutet. Statt dessen erzähle ich etwas anderes: Die Software, die wir schreiben, ist eng mit einem solchen Produktlebenszyklus gekoppelt.
Vielleicht schreiben wir Software, die selbst ein Produkt ist, dann hat sie selbst einen Produktlebenszyklus. MS Word ist ein typisches Beispiel. Word 95, Word 97, Word 2000, Word XP, Word 2003, Word 2007, Word 2010, Word 2013, Word 2016… Was wir hier sehen, ist ein typischer Produkt-Relaunch alle paar Jahre.
Vielleicht schreiben wir auch Software in Produkten — in Waschmaschinen, Autos, Computertomographen und Spielzeug. Auch dann ist klar, dass es hier einen Produktlebenszyklus gibt, der den Lebenszyklus der Software bestimmt.
Selbst, wenn wir Software schreiben, die nur hausintern verwendet wird, hat sie einen Lebenszyklus. Entweder, weil die Leistung die die Software dem Unternehmen bringt, quasi ein internes Produkt ist oder weil die interne Software zur Bereitstellung eines extern vertriebenen Produktes dient, das einem Lebenszyklus unterliegt.
Wie genau die Lebenszykluskurve aussieht, kann sehr unterschiedlich sein. Vielleicht gibt es regelmäßige Relaunches (Word), vielleicht sind solche gar nicht möglich (Diskette). Vielleicht gibt es einen kurzen Hype oder einen Flop und in ganz wenigen Fällen gibt es auch Produkte, die so zeitlos sind, dass man sie fast nicht sterben sieht. Manchmal ist der Niedergang plötzlich (z.B. durch ein starkes Konkurrenzprodukt) und manchmal schleichend. Fakt ist: Einen solchen Lebenszyklus gibt es quasi immer.
Application Lifecycle Management (ALM)
OK, Software hat also einen Lebenszyklus. Und was fangen wir mit der Erkenntnis nun an? Tatsächlich irgendwie alles uns nichts. Der Software-Lebenszyklus erweitert erstmal ihren Entwicklungszyklus. Vor der Entwicklung gibt es eine Art Ideenphase, nach der Entwicklung eine Wartungsphase und eine Phase, in der man die Software ablöst. Auch das ist erstmal nicht viel mehr als eine banale Erkenntnis.
Wenn wir nach Software für ALM suchen, sehen wir, dass ganz verschiedene Produkte sich mit dem Begriff „ALM“ schmücken. Dazu zählen Jira, GitLab und Enterprise Architect. Hier ist ALM der Marketing-Begriff der sagen will „dieses Produkt kannst du von vorne bis hinten im Lebenszyklus einer Anwendung einsetzen“. So richtig konkret wird da nichts. Marketing eben.
ALM ist also nicht die eine Aufgabe, sondern alles Mögliche. Alle Prozesse, die irgendwie in einer IT-Organisation stattfinden, sind Teil von ALM: Konzeption, Entwicklung, Bugfixing, Betrieb und Wartung, Support, Weiterentwicklung, Ablösung, Migration — alles. Demnach ist es — zumindest von diesem generellen Standpunkt aus betrachtet — nicht sonderlich sinnvoll zu sagen „lasst uns mal ALM machen“.
Wenn wir nach dem Sinn von ALM fragen, dann müssen wir uns Gedanken über den Kontext machen, in dem der Begriff gebraucht wird. Neben dem Marketingbegriff für verschiedene Softwareprodukte ist ALM auch ein Begriff, der im Bereich Consulting relevant ist. Hier ist er quasi Marketing-Begriff für Beratungsleistungen. Berater verkaufen, dass sie sich quasi alle Prozesse, die mit Software zu tun haben, angucken und Verbesserungsvorschläge machen. Umgekehrt brauchen Berater irgendwas, an dem sie sich entlang hangeln können, wenn sie die Prozesse eines Unternehmens angucken — eine Art Checkliste. In diesem Kontext stehen Standards wie ISO 24748-1 [2] und die Application Services Library (ASL) — quasi die Schwester von ITIL.
Nun hat ITIL nicht ganz zu unrecht den Ruf, schwergewichtig und bürokratisch zu sein — quasi das Gegenteil von moderner Softwareentwicklung, die sich auf agile Werte stützt. ASL wird da nicht grundlegend anders sein. Deshalb sehe ich den Nutzen dieser Standards höchstens in drei Aspekten: Zum einen definieren sie Begriffe für Dinge, die man eh schon tut (und Begriffe haben, ist eine gute Sache). Zum zweiten bilden sie eine Zusammenstellung an Dingen, die wichtig sein können, aber nicht müssen. Man kann da mal drauf gucken und sich inspirieren lassen. Vielleicht braucht man davon ja etwas. Und zum dritten kann diese Liste als Anforderungsgrundlage für Outsourcing dienen. Wenn man sich von einem externen Dienstleister Software bauen lässt, sollte man sich darüber Gedanken machen, was Teil des Vertrages wird. Man sollte klären, was wer leistet: Bugfixing, Support, Wartung, Versionsupdates, etc.
Kurz: ALM ist eine Sammlung an Anforderungen (und ein Marketingbegriff).
Data/Information Lifecycle Management (DLM/ILM)
Vieles von dem, was für ALM gilt, gilt auch für Data Lifecycle Management — nur eben für Daten. Daten werden gesammelt/erhoben/berechnet, aufbewahrt, aktualisiert, genutzt und irgendwann wieder gelöscht. Wichtiger Teil sind gesetzliche Aufbewahrungs- und Löschfristen. Auch das ist so eine Mischung aus Anforderungen, Begriffsdefinition, Marketing und Consulting-Konzept. Sicherlich nicht nutzlos, aber eher interessant für die Fachseite und für Requirements Engineering.
ALM — was was bleibt übrig?
Lassen wir jetzt einfach mal Marketing, Standards und Consulting-Zeug außen vor. Bleibt noch irgendetwas Sinnvolles, das wir da rausziehen können? Dazu erinnern wir uns daran, was eigentlich unser Ziel war. Lifecycle Management ist ja kein Selbstzweck, vielmehr soll es ein Mittel sein, technisch wichtige Aspekte dem Management begreiflich zu machen.
Wenn wir sagen, wir müssen diese Legacy-Anwendung ablösen, dann klingt das technischer Spielerei oder zumindest nach „nicht ganz so wichtig“. Wenn wir stattdessen sagen, wir machen Application Lifecycle Management und diese und jene Anwendung ist jetzt in der Ablösephase, dann ist das inhaltlich dasselbe, aber es klingt wichtiger. OK, das ist jetzt vielleicht ein bisschen frech ausgedrückt. Es geht nicht (nur) darum, das hochtrabend klingen zu lassen, sondern darum, einen Prozess zu etablieren, wie man dem Management regelmäßig technische Notwendigkeiten klar macht. Bei ALM geht es also um Kommunikation von der Technik ins Management. Beispiele:
- Von dieser Anwendung gibt es eine neue Version, die bereits im Einsatz ist. Beide Versionen zu betreiben und zu warten ist unnötiger Aufwand. Deshalb ist eine vollständige Umstellung auf die neue Version nötig, sodass wir die alte abschalten können.
- Diese Anwendung ist zugekauft, wird vom Hersteller aber nicht mehr weiter entwickelt. Wir sollten uns nach Alternativen umsehen.
- Diese Anwendung wird nur noch für ein Produkt benötigt, das kaum noch relevant ist. Die Wartungskosten der Anwendung sind höher als der Gewinn durch das Produkt. Wir sollten die Anwendung abschalten und damit dann auch den Lebenszyklus des Produkts beenden.
- Der Relaunch dieses Produkts erzeugt vermutlich wieder mehr Last auf dieser Anwendung. Wir müssen sie erneuern.
- Das Produkt ist noch sehr relevant. Die zugrunde liegende Anwendung ist aber veraltet. Wir brauchen zwar keinen Relaunch des Produkts, aber einen „Relaunch der Anwendung“, d.h. technische Wartung bzw. Erneuerung.
Technology Radars
Wir hatten ja schon festgehalten, dass LCM außerhalb von Management-Kreisen keinen allzu guten Ruf geniest. Was hingegen meist relativ positiv gesehen wird, sind Technologieradars. Immer wieder schießen neue Technologien aus dem Boden und man muss bewerten, was man damit nun anfängt. Sind sie interessant bzw. hilfreich? Sind sie ausgereift? Sollte man sie quasi überall einsetzen, weil state-of-the-art? Oder sollte man sie erstmal nur vorsichtig ausprobieren — in Projekten, die das Risiko verkraften?
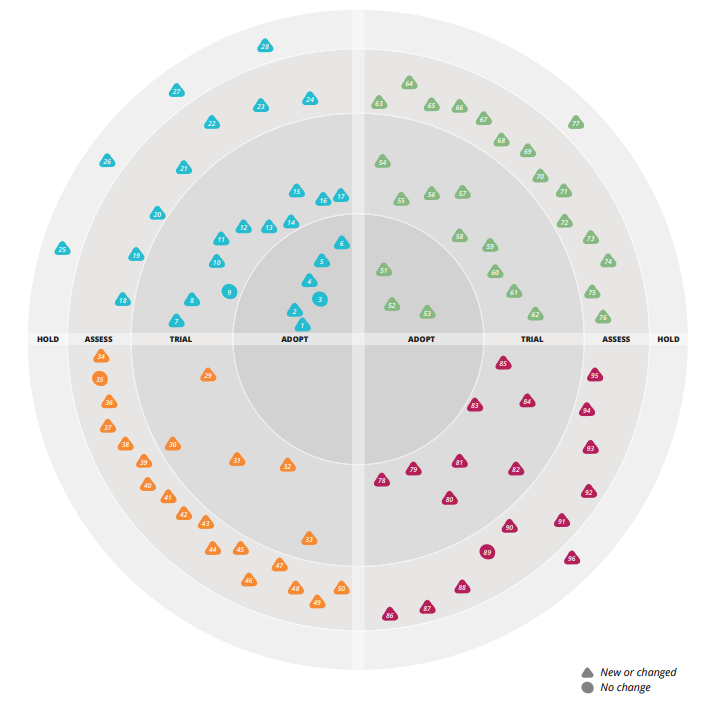
Eine Technologie kann dabei ganz unterschiedlichen Kategorien angehören: Thoughtworks unterscheidet die vier Kategorien Techniques, Tools, Platforms und Languages & Frameworks. Wenn man ein eigenes Radar baut, kann man natürlich andere Kategorien wählen. Die von Thoughtworks sind auf die Bedürfnisse von Thoughtworks zugeschnitten und nicht notwendigerweise für den eigenen Fall die hilfreichsten. Alternative Kategorien könnten sein: Libraries, Betriebssysteme, Treiber, Datenhaltung, Infrastruktur, … vielleicht will man auch Frontend- von Backend-Technologien trennen, etc.
Jeder Technologie wird eine Art Rating oder eine Phase zugeordnet:
- Assess: Neue Technologie. Kann man sich mal angucken.
- Trial: Vielversprechende Technologie. Sollte man in kleineren Projekten mal vorsichtig ausprobieren.
- Adopt: Etablierte Technologie. Sollte man nutzen. Das ist state-of-the-Art.
- Hold: Finger weg. Alte Technologie, Irrweg oder Anti-Pattern.
Wieder haben wir eine Art Lebenszyklus. Eine neue Technologie taucht auf, wird beobachtet, ausprobiert, eingesetzt und irgendwann wieder ausgebaut. Manche Technologien kommen auch früher in den Zustand „Hold“, weil konkurrierende Technologien zu bevorzugen sind oder weil es sich von vornherein um Irrwege handelt.
Wer sich noch mehr TechRadars angucken will: Porsche, Zalando und andere stellen ihre ins Netz.
Technology Lifecycle Management (TLM)
Technologie-Radars sind dazu da, allgemein und mehr oder weniger losgelöst von einer konkreten Softwarelandschaft die Entwicklung verschiedener Technologien zu beobachten. „Technologie X hab ich auf dem Radar“. Das ist super für Consulting-Buden, die Expertise verkaufen, aber wenn ich in einem Unternehmen arbeite, das selbst eine größere Softwarelandschaft hat, reicht das nicht ganz aus. Der Blick über den Tellerrand ist wichtig, aber man muss auch auf den eigenen Teller gucken und die Suppe auslöffeln, die man sich eingebrockt hat.
Wenn man mit einem Technologie-Radar die eigene Software analysieren will, muss man es ein wenig aufbohren. Und dann sind wir bei etwas, das man Technology Lifecycle Management (TLM) nennen kann [3]. Hier gucken wir uns nicht ganze Anwendungen an (wie bei ALM), sondern einzelne Technologien, die Teil dieser Anwendungen sind: Libraries, Frameworks, Tools, etc. Wir sehen hier schon die große Verwandtschaft mit dem TechRadar.
Wir erinnern uns wieder an unser Ziel: Wir wollen technische Notwendigkeiten für das Management verständlich machen. Dazu brauchen wir selbst einen Überblick darüber, was denn diese technischen Notwendigkeiten sind. Welche Libraries brauchen ein Update? Welche Technologien wollen wir loswerden? Welche würden uns Nutzen bringen? Wie kann man das Ganze priorisieren? Mit diesem Ziel bohren wir jetzt also unser TechRadar auf.
Zum einen reicht es nicht, Technologien als Ganzes zu betrachten. Ein wichtiger Teil des technisch Notwendigen sind Versionsupdates. Ich rede hier nicht von Bugfix-Releases (die mit anderer Micro-Version). Alleine schon aus Security-Gründen hat man hier am besten automatisierte Dependency-Checks oder noch besser automatisierte Updates. Außerdem sind solche Updates i.d.R. schneller gemacht als beschrieben und kommuniziert. Also macht man sie einfach.
Updates der Major-Version ziehen aber Breaking Changes mit sich. Das ist unbequem, wird ggf. vergessen und im schlimmsten Fall verschleppt bis man einen riesigen Berg an notwendigen Legacy-Updates hat. Das wollen wir natürlich vermeiden. Die Umstellung von Jackson 1 auf Jackson 2, von JUnit 4 auf JUnit 5, von Java 8 auf Java 11, von SpringBoot 1 auf Spring Boot 2, etc. Das alles erfordert größere oder kleinere Code-Änderungen. Und wenn man diese nicht nur in einer Anwendung hat, sondern in Hunderten, ist das eine gewichtige Aufgabe. Also müssen wir für unser Radar einzelne Versionen berücksichtigen. Jackson 1 ist Hold, Jackson 2 ist Adopt. Wenn ich in manchen Anwendungen noch Jackson 1 im Einsatz habe, sollte ich updaten.
Außerdem ist es hilfreich, die Hold-Phase aufzuteilen: Keep (neue Anwendungen sollten das nicht mehr nutzen, aber es ist noch nicht notwendig, alte Anwendungen im großen Stil um zu stellen) vs. Hold (weg mit dem Zeug). JUnit 5 würde ich aktuell mit Adopt bewerten, JUnit 4 mit Keep und noch ältere Versionen mit Hold. Wenn es nur eine relevante Version gibt: umso besser. Dann brauche ich die Details nicht. Wie gesagt: Es geht hier um Major-Versionen, also um die mit Breaking Changes. Die anderen sind nicht der Rede wert (zumindest aus Sicht von TLM; Security ist was anderes).
Hier zeigt sich der klare Unterschied zur Versionsbetrachtung der Security. Als Security-Gründen ist der Einsatz von JUnit 4 kein Problem und vermutlich wird es auch nie zum Problem werden. Immerhin wird das nur zum Testen verwendet und landet nie in der Produktivumgebung. Aus Wartungsgründen kann JUnit 4 trotzdem irgendwann ein gewaltiges Problem werden. Sehr viel Code hat eine Abhängigkeit auf JUnit 4. Wenn man viele Anwendungen mit vielen Tests hat, bedeutet die Umstellung sehr viel Arbeit. Angenommen JUnit 4 würde irgendwann mit neueren Java- oder SpringBoot-Versionen inkompatibel werden. Aktuell ist das nicht ab zu sehen, aber ausgeschlossen ist es nicht. Auf ähnliche Weise könnten in Zukunft andere Libraries und Tools mit JUnit 4 inkompatibel werden. Außerdem wird man in Zukunft weniger Doku und Tutorials für JUnit 4 finden und weniger neu ausgebildete Entwickler, werden sich damit auskennen. So weit ist es noch nicht, aber irgendwann wird es soweit sein. Eine große Codebasis, die noch auf JUnit 4 setzt, ist also durchaus ein gewisses Risiko, das man bewerten muss — nicht aus Security-Gründen, aber aus Wartungsgründen.
Umgekehrt sind Bugfix-Versionen für Security sehr wichtig. Für TLM sind sie erstmal außen vor, weil der Aufwand deutlich geringer ist und sich die Sache gut automatisieren lässt. Wobei man ggf. die Automatisierung, die aus Security-Gründen im Einsatz ist, ggf. auch für TLM zum Teil mitnutzen kann.
Malen wir also mal den Technologie-Lebenszyklus auf:
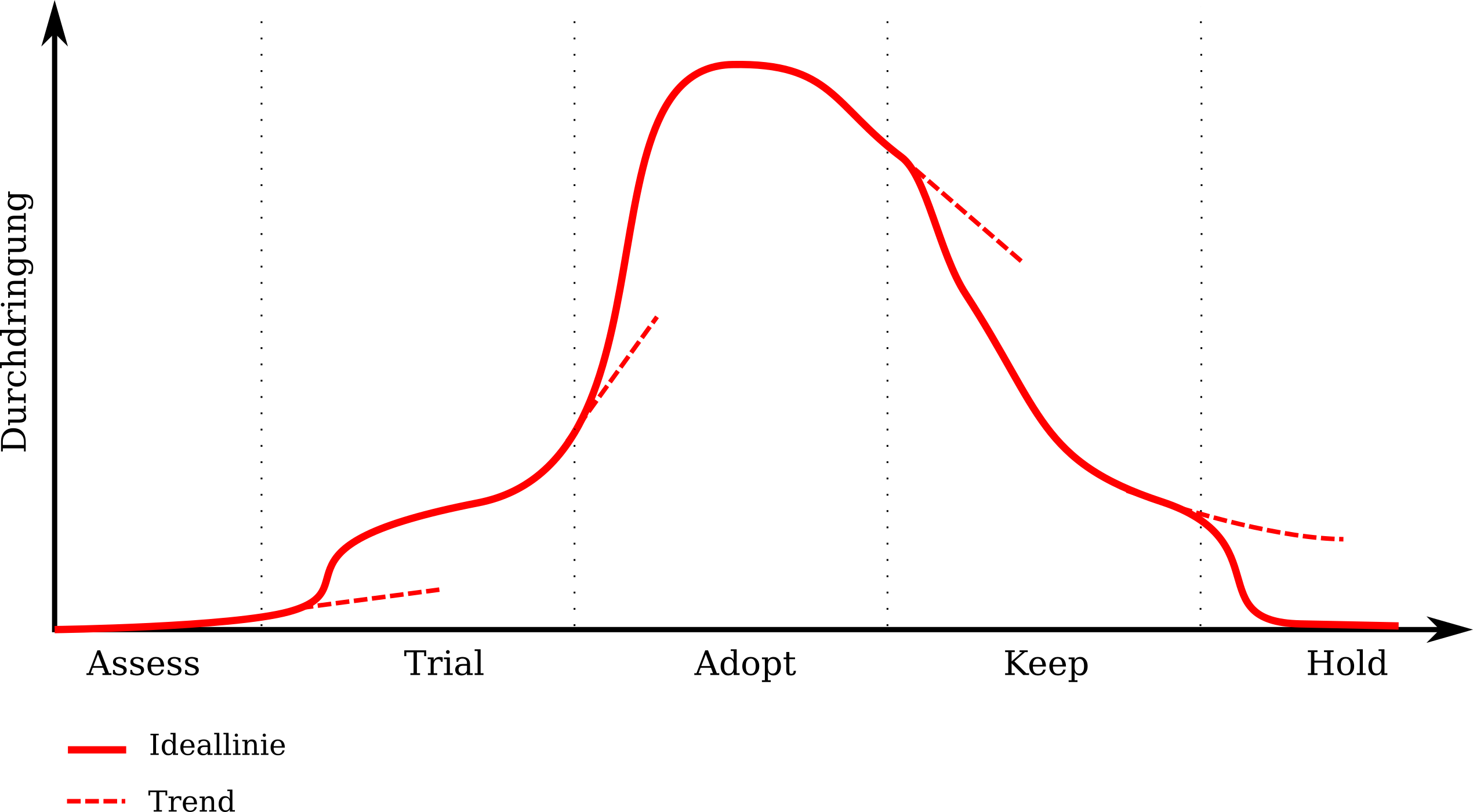
Eine Technologie wird beobachtet (Assess), ausprobiert (Trial), eingesetzt (Adopt), noch behalten, aber nicht mehr neu eingebaut und langsam reduziert (Keep) und irgendwann ganz ausgebaut (Hold). Die Y-Achse im Diagramm ist hierbei die Durchdringung, also quasi die Frage Wie viele Zeilen meines Codes haben eine Abhängigkeit auf diese Technologie? also letzten Endes Wie viel Code muss ich ändern, wenn ich diese Technologie wieder loswerden möchte?
Achtung: Ich hab hier absichtlich „Zeilen Code“ geschrieben, nicht etwa „Anzahl der betroffenen Artefakte“. Ich kann eine Dependency in quasi jedem Artefakt haben, die aber nur jeweils eine einzige Zeile Code betrifft. Da ich dann immer noch jedes Artefakt einmal anfassen muss, ist die Durchdringung trotzdem nicht klein, aber ggf. erträglich. Muss ich aber quasi alle meine Anwendungen neu schreiben, weil ich auf AngularJS gesetzt habe und die neue Version „Angular 2“ (fort folgende) komplett anders funktioniert, ist das eine ganz andere Hausnummer.
Die einzelnen Phasen können unterschiedlich lang sein. Insbesondere Assess und Keep sind mitunter deutlich länger als die anderen.
Die gestrichelten Linien zeigen an, wie sich die Durchdringung ändern würde, wenn der Phasenübergang nicht erfolgt. Der Übergang ist also jeweils ein bewusster Schritt:
- Assess: Wir wollen die Technologie beobachten. Wir lesen Blogs, hören Vorträge, machen vielleicht mal ein Tutorial.
- Trial: Die Technologie ist es wert, wirklich ausprobiert zu werden. Ohne den bewussten Schritt, das zu tun, würden wir zu wenig lernen und ggf. den Fortschritt verschlafen. Lasst uns das mal in einem kleinen abgegrenzten Projekt mit geringem Risiko ausprobieren.
- Adopt: Die Technologie hat sich bewährt und setzt sich durch. Noch wissen davon aber zu wenige in der Organisation. Wir erzählen überall herum, dass die Technologie eingesetzt werden sollte.
- Keep: Es gibt bessere Alternativen, aber die kennt noch nicht jeder. Lasst uns überall herum erzählen, welche das sind und wie man da hin migriert. Der Rückbau passiert nebenher mit den Projekten, die kommen.
- Hold: Wir müssen die Technologie endlich loswerden. Das geht aktuell zu langsam. Lasst uns noch eine kurze Anstrengung unternehmen und den Rest ausbauen.
Dabei bedeutet „Hold“ nicht zwangsweise „old“. Ja, das ist ein Lebenszyklus, den quasi jede Technologie durchläuft. Trotzdem kann es auch andere Gründe für eine Einsortierung geben. Beispielsweise Lizenzprobleme, Inkompatibilitäten, Instabilität, Bugs, etc. Deshalb ist es gerade bei „Hold“, manchmal auch bei anderen Kategorien, sinnvoll, die Gründe für die Eingruppierung zu kommunizieren (was i.d.R. bedeutet, sie auf zu schreiben).
Ähnlich ist es mit „Trial“. Trial bedeutet nicht zwangsweise neue Technologie. Trial kann auch bedeuten, dass die Technologie bereits gut abgehangen ist, aber dass man entweder in der Organisation nicht genug Erfahrung damit hat oder dass diese Erfahrungen nicht positiv genug waren, sodass eine Einstufung in „Adopt“ nicht sinnvoll erscheint. So kann es sein, dass es für einen bestimmten UseCase nur eine bekannte Technologie gibt und diese ist seit Jahren etabliert aber nur mäßig gut. Dann ist diese Trial, was allen anzeigt: „Kann man einsetzen, seid aber mal vorsichtig damit. Und wenn jemand eine gute Alternative kennt, sagt Bescheid.“
Auch kann man eine etablierte, aber alte Technologe schon auf Keep setzen bevor es einen Nachfolger gibt. Alleine schon um anzuzeigen, dass es diese Probleme gibt und dass wir uns jetzt um einen Nachfolger kümmern müssen.
Irgendwo auf dieser Ebene kann ich jede Technologie verorten. Liegt ein Punkt nicht auf der gezeigten Ideallinie, gibt es wahrscheinlich Arbeit. Wir können die Ebene in einzelne Teilbereiche aufteilen:
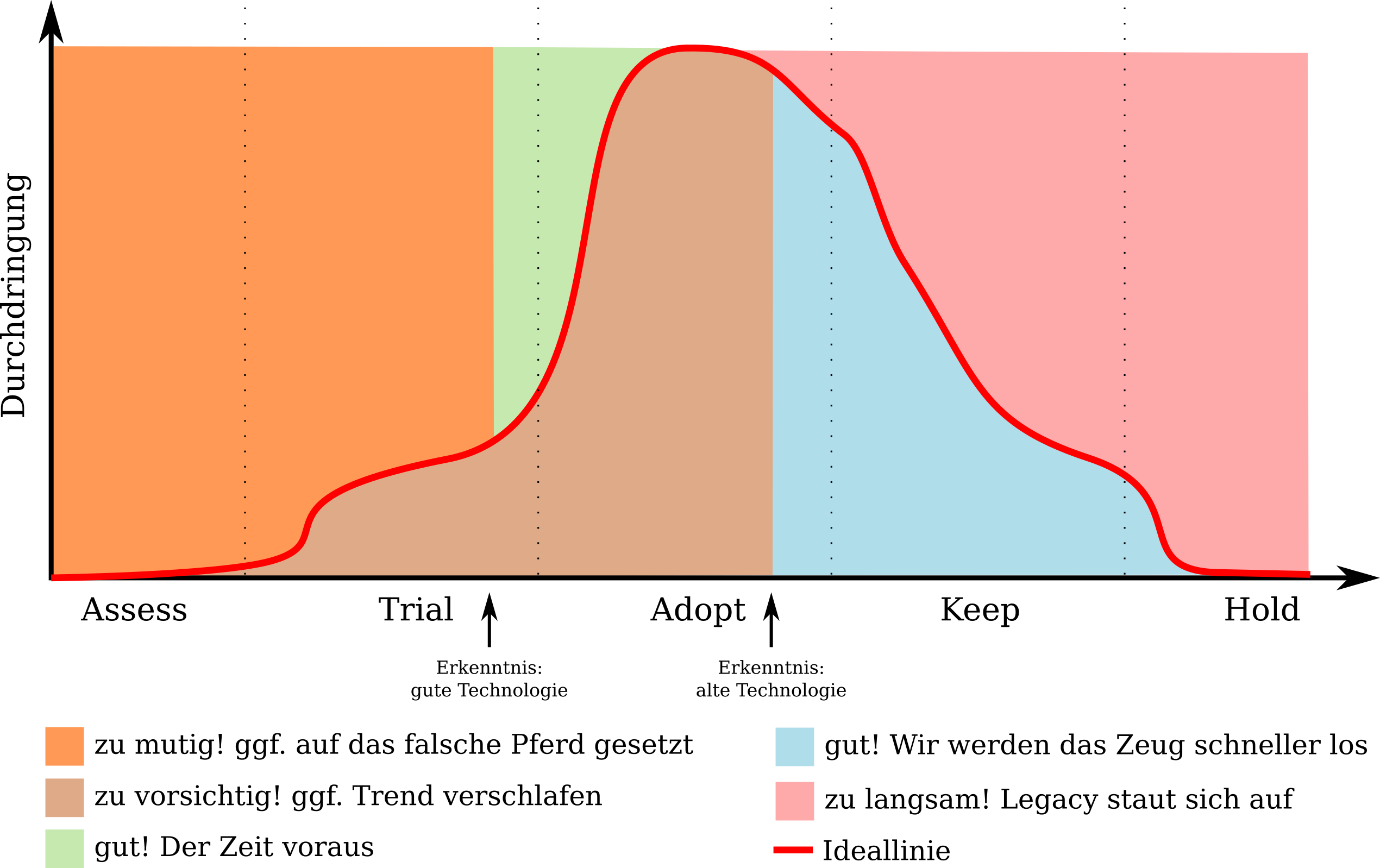
Je nachdem, wo auf der Fläche meine Technologie verortet ist, sind andere Dinge zu tun.
Team vs. Organisation
Die Bewertung der einzelnen Technologien kann sich unterscheiden, je nachdem, auf welcher Größenordnung man die Betrachtung durchführt.
- Eine Technologie kann für die Organisation als Ganzes vollkommen OK sein (Adopt). Ein Team kann sich aber dafür entscheiden, diese Technologie nicht ein zu setzen (Hold). Das kann sogar eine ziemlich sinnvolle Sache sein, wenn beispielsweise das Team entscheidet, die Anzahl der verwendeten Technologien zu begrenzen (MIMC, UP, UFT).
- Ein Team kann ambitionierter sein, als die Organisation und eine Legacy-Technologie schneller loswerden wollen.
- Je nach Team bzw. Projektkontext kann auch das Ausprobieren neuer Technologien einfacher oder schwerer bzw. sinnvoller oder riskanter sein.
- Wenn in einem Team eine Technologie weiter verbreitet ist, als im Rest der Organisation, unterscheidet sich offensichtlich die Durchdringung. Das wiederum kann dazu führen, dass sich die Bewertung einer Technologie unterscheidet. Wenn ein Team bereits genug Erfahrung mit einer Technologie gesammelt hat, kann diese früher Adopt werden, als im Rest der Organisation. Das gilt natürlich auch umgekehrt: Wenn Erfahrung fehlt, muss man die ggf. erst sammeln (Trial).
- In manchen (seltenen) Fällen kann auch ein Team bzw. Projekt Sonderanforderungen haben und eine Technologie, die im Rest des Unternehmens nicht eingesetzt werden sollte (Hold), doch einsetzen müssen und deshalb als Adopt deklarieren.
Relevanz
Heißt das jetzt, dass ich alle Technologien, die wir einsetzen, irgendwie da einsortieren muss? Und die, die irgendwann mal relevant werden könnten auch? OK, offensichtlich wäre das ein bisschen zu viel des Guten. Bei Tausenden von Libraries in diversen Versionen, die typischerweise in einer größeren Softwarelandschaft im Einsatz sind, wäre das ein Vollzeit-Job, wenn nicht mehr. Deshalb erinnern wir uns wieder an unser Ziel: Es geht um den Überblick über die die Kommunikation von technischen Notwendigkeiten. Um das wichtige Zeug.
Aber was ist denn nun wichtig? Auch dafür gucken wir uns wieder unser Ziel an. Was ist das, was wir vermeiden wollen? Wir sind angetreten, zu vermeiden, dass 50 Joghurts auf einmal schimmeln. Einen Joghurt nach dem anderen kann ich essen, aber nicht 50 auf einmal. Ein Library-Update kann ich machen. Aber wenn ich in 50 Anwendungen jeweils 30 Libraries updaten muss, bin ich eine Weile beschäftigt und kann in der Zeit keine Features umsetzen. Der Laden steht, alle gucke bedröppelt und der Chef fängt an zu weinen. Ich muss mir also genau das angucken, was mir in Zukunft Arbeit machen könnte. Ich muss mir das angucken, was ich bereuen könnte, übersehen oder vernachlässigt zu haben. Effektiv handelt es sich also um die oben bereits beschriebene Durchdringung — bzw., wenn es um die Betrachtung zukünftiger Technologien geht, die Relevanz, also die potenziell zukünftige Durchdringung. Wenn ich viel Code anpassen muss, wenn ich also viel Code investiert habe, muss ich mir das genauer angucken. Wenn ich wenig investiert habe, lohnt der Aufwand des Prozesses nicht.
Jetzt kann man sich natürlich fragen, ob es weitere Aspekte gibt. Wie sieht es mit Security aus? Was ist das Szenario? Angenommen eine Library hat eine Sicherheitslücke und ich muss updaten. Oder aber es gibt eine Sicherheitslücke und kein Update, sodass ich einen Workaround implementieren oder die Lib komplett ausbauen muss. Ist die Durchdringung der fraglichen Library hoch, hab ich viel zu tun. Ist die Durchdringung aber gering, hab ich nicht viel Arbeit. Ja, ich muss etwas tun. Aber dafür hab ich Tooling. Im Idealfall ist das dann ein Knopf den ich drücken muss, weil Depdendabot die Lücke bemerkt und automatisch einen Pull Request gestellt hat. Mit meinem Klick merge ich den Pull Request, der CI-Server lässt die Tests durchlaufen, baut eine neue Version meines Artefakts, macht ein Release und schiebt es in Produktion. OK, so weit sind wir noch nicht ganz, aber selbst, wenn nicht ganz so viel Automatisierung da ist: Ist die Durchdringung gering, hab ich nicht so viele Schmerzen.
Zweiter Versuch: Was ist mit der Verwendung in kritischen Artefakten? Angenommen die fragliche Technologie ist in einem sehr zentralen Artefakt verbaut und wenn das nicht funktioniert, bricht eine große Katastrophe über uns herein. Auch hier stellt sich wieder die Frage nach der Durchdringung. Bei hoher Durchdringung bedeutet das, ich muss in meinem kritischen Artefakt viel ändern. Das bedeutet viel Aufwand und womöglich ein hohes Risiko (durch die große Änderung). Ist aber nur eine einzige Zeit Code in meinem kritischen Artefakt betroffen und das Update bzw. die Ablösung trivial, dann ist das Tagesgeschäft und nicht Wert, dass man in einem unternehmensweiten Gremium darüber debattiert.
Dritter Versuch: Angenommen etwas hat zwar keine hohe Durchdringung, aber es sorgt gerade für Verunsicherung. Irgendjemand hat gehört, dass Technologie X wichtig oder unsicher oder abgekündigt ist. Das wäre tatsächlich noch ein Grund, sich damit zu befassen. Immerhin geht es bei LCM ja um Kommunikation und darum, Unsicherheit zu nehmen. Wenn etwas gerade heiß diskutiert wird — sei es im positiven oder im negativen Sinne — dann sollten wir eine Antwort auf die Frage haben, wie wir damit umgehen. Alles andere ist mehr als nur kontraproduktiv.
Somit ist also (potenzielle) Durchdringung bzw. der Invest (oder wie auch immer man das nennen will) das quasi einzige Relevanzkriterium für die Aufnahme ins TLM. Zu dieser objektiven Relevanz gesellt sich nur noch die subjektive bzw. angenommene Relevanz.
Aber selbst das kann am Anfang relativ viel sein. Es ist nicht sonderlich sinnvoll, erstmal alle Technologien zu erheben, dann alle zu bewerten und dann zu gucken, was man daraus macht. Das dauert schlicht und einfach viel zu lang. In der Zeit hätte man für die ersten Technologien bereits Erkenntnisse sammeln können. Besser also man fängt mit einer Liste von 10 oder 20 Technologien an und erweitert diese dann schrittweise. Die Liste muss nicht perfekt sein — zur Not reicht sogar eine willkürlichen Liste. Hauptsache man fängt an. Im besten Fall startet man mit den Technologien, bei den wahrscheinlich Handlungsbedarf besteht: Die ältesten Technologien mit der weitesten Verbreitung, den größten Sicherheitslücken und dem größten Schmerz.
Abgrenzung ALM vs. TLM
Falls man sich den Spaß geben will ALM und TLM voneinander ab zu grenzen: Was gehört denn nun zu was? Selbstentwickelte Anwendungen sind klar ALM und OpenSource-Libraries sind klar TLM. Wie aber sieht es mit selbstentwickelten Libraries aus? Oder mit zugekauften Anwendungen? SSH ist ein Programm, also eine Anwendung. Aber intuitiv würde man es wie eine Library betrachten, nicht?
Der Kernunterschied zwischen ALM und TLM ist der Lebenszyklus und zwar der verbundene Produktlebenszyklus. Bei ALM geht es um Anwendungen, die man selbst entwickelt. Hier gibt es einen Produktlebenszyklus, den man selbst in der Hand hat — zumindest zu einem gewissen Teil. Wie lange die Anwendung supported wird, wann es updates gibt, wie schnell Bugs und Sicherheitslücken gefixt werden. Das kann man alles selbst bestimmen. In der Regel gibt es feste interne Ansprechpartner und man hat organisatorische Freiheiten, man kann das Produktmanagement nach Einschätzungen fragen, wie sich die Produkte weiterentwickeln werden, etc.
Anders sieht es bei TLM aus. Der Technologielebenszyklus einer Library hat nichts mit dem Produktlebenszyklus der eigenen Produkte zu tun (ganz im Gegensatz zum Lebenszyklus des Provisionierungssystems oder des Shops zum Verkauf der eigenen Produkte). Die Einflussmöglichkeiten auf den Lebenszyklus sind auch eher begrenzt. Ja, man kann OpenSource-Libraries forken, wenn diese vom Maintainer fallen gelassen werden oder man mit der Entwicklungsrichtung nicht einverstanden ist. Häufig ist das aber eher unrealistisch und wird vergleichsweise selten gemacht. Es gibt auch i.d.R. keine dedizierten internen Ansprechpartner für solche Libraries. Oder wer ist bei euch Ansprechpartner für AngularJS und wie sind die Handlungsmöglichkeiten, wenn die neue Version auf einmal fundamental inkompatibel ist? Manche Dinge hat man nicht in der Hand.
So wird auch klar, dass SSH wirklich keine Anwendung im Sinne von ALM ist, sondern eher zu behandeln ist wie eine Library. Bei zugekauften Anwendungen kann es interne Ansprechpartner geben, ggf. gibt es Supportverträge und mit ein wenig Geld lassen Softwarehersteller auch auf sich einwirken. In solchen Fällen sind zugekaufte Anwendungen, Anwendungen im Sinne des ALM. Je geringer aber die Einflussmöglichkeiten, desto eher ist es eine Technologie.
Akzeptanz
Das Wort Lifecyclemanagement lässt so manchen meiner Kollegen erschaudern. Kein Wunder — es kommt ja auch das Wort Management darin vor.
Und klar, wer Risiken nur managt und ihnen nicht begegnet, wer Security nur managt statt Sicherheitslücken zu stopfen, wer Bugs lieber managt als fixt, der arbeitet am Kern des Problems gehörig vorbei. Und genauso, wie man mit Risiken, Security und Bugs falsch umgehen kann (und wir alle haben das in der ein oder anderen Form sicher schon erlebt), kann man natürlich auch mit LCM falsch umgehen. Das ist die Befürchtung die — vielleicht nicht ganz unberechtigt — mitschwingt. LCM richtig zu machen ist schwer. Entweder ist es ein Papiertiger oder ein Bürokratiemonster und im schlimmsten Fall sogar beides. Den richtigen Weg zu treffen, ist nicht leicht. Das Problem gar nicht erst an zu gehen, ist aber auch nicht unbedingt richtig.
Dabei ist LCM doch eigentlich genau das, was wir die ganze Zeit schon immer wollten: Dass die Organisation uns zu hört und wir technische Erneuerung kontinuierlich angehen, statt zu verschlafen. Wie aber kommuniziert man, dass es genau darum geht?
So ein richtiges Patentrezept hab ich da noch nicht gefunden. Ich versuche den Begriff „Lifecycle Management“ auf der Arbeitsebene zu vermeiden. Einen besseren Begriff hab ich aktuell aber auch nicht. Vielleicht „kontinuierliche Technologiebetrachtung“, „Technologieanalyse“ oder „Wartungsbedarfsanalyse“? So richtig cool klingt das alles nicht.
Aktuell versuche ich den Begriff einfach zu vermeiden. Zu meinen Kollegen sage ich sowas wie „Ich hab den Auftrag, Technologien zu ermitteln, die wir erneuern müssen. ggf. kriegen wir dafür dann Zeit. Welche soll ich auf die Liste schreiben?“ Und wenn doch mal der Begriff fällt, dann erkläre ich ausschweifend — wie in diesem Blogartikel — die Hintergründe oder ich erzähle vom Loriot-Test.
Der Loriot-Test
Alle, die bis jetzt durchgehalten haben, nur um zu lesen, was ich mit dem Loriot-Test meine: Respekt! OK, worum gehts? Da wir nicht in einem Loriot-Sketch enden wollen, müssen wir a) Verhältnismäßigkeit wahren und b) unser Ziel im Blick haben. Verhältnismäßigkeit sollte klar sein. Unser Ziel ist es — wie schon mehrfach erwähnt — einen Überblick über technische Notwendigkeiten zu erlangen, diese zu kommunizieren und technologisch am Ball zu bleiben.
Deshalb fragen wir uns eine zentrale Frage: „Was würde Loriot tun?“ So finden wir treffsicher die Situationen, Verhaltensweisen und Irrwege, die wir dringend vermeiden wollen.
„Mein Name ist Lohse, ich kaufe hier ein.“ — Loriot in Pappa ante portas
Was würde also Loriot tun?
- Loriot würde LCM nicht machen um die genannten Ziele zu erreichen, sondern um wichtig zu sein.
- Loriot würde sich Standards nicht angucken, um da hilfreiche Ideen raus zu zielen, sondern um sie Wort für Wort um zu setzen. — Weil es da steht.
- Bei Loriot wäre die Haupt-Kommunikationsrichtung nicht von den Teams nach oben, sondern von der unergründlichen Weisheit des Managements nach unten zu den dummen Teams.
- Deshalb würde Loriot auch darauf bestehen, jede neue Technologie vorher ab zu nicken, bevor ein Team sie einsetzen darf.
- Den Teams ist sowieso nicht zu trauen. Ja, die beschäftigen sich gerade intensiv mit einem Projekt, mit den ganzen Rahmenbedingungen und Gegebenheiten. Ja die Kollegen da haben wahrscheinlich gerade eben die Doku gelesen. Wahrscheinlich haben sie sogar eine ganze Menge praktische Erfahrung mit der Technologie. Aber was zählt das schon? Sie sind nicht Teil des Gremiums und deshalb per Definition unwichtig.
- Jegliche Kategorisierung der Technologien würde Loriot natürlich höchstpersönlich vornehmen. Auf keinen Fall würden die Teams, die tagtäglich mit den Technologien arbeiten, irgendwas mit der Kategorisierung zu tun haben.
- Für Loriot ist der Hauptzweck von LCM, sicherzustellen, dass ja kein Team unerwünschte Freiheiten hat. Standardisierung ist wichtig und Normen sind heilig. Das Gremium bewahrt die Teams vor falschen Entscheidungen.
- Außerdem ist für Loriot natürlich jedes Problem ein Nagel auf den man mit dem Hammer LCM einschlagen kann. Die Software ist instabil und hat Bugs? Liegt bestimmt an zu sorglos verwendeten Libraries. Wir sollten darüber im Gremium debattieren und ggf. ein paar Technologien verbieten. Das hilft bestimmt mehr als die automatisierten Tests, von denen die Entwickler schwafeln.
- In der Welt von Loriot würde LCM nicht dazu führen, dass Technologiewechsel kontinuierlich geschehen und dass neue Technologien regelmäßig evaluiert werden. Vielmehr würde natürlich das Gegenteil der Fall sein. Da Teams nur dann Technologien ausprobieren dürfen, wenn das allwissende Gremium das in einem bürokr… in einem geregelten Prozess erlaubt hat, wird kein Team es auch nur wagen, etwas unbekanntes anzufassen (oder aber versuchen, den Prozess zu unterlaufen). Die perfekte Standardisierung ist dann erreicht, wenn alle die Technologie einsetzen, die man sich vor 20 Jahren mal ausgemalt hat. Schöne neue Welt!
Es ist schön zu sehen, dass wir in unserem Gremium den Loriot-Test anwenden. Gefühlt wittert jeder von uns an jeder Ecke unnötige Bürokratie. Wir pfeifen uns gegenseitig zurück und wenn wir uns streiten, dann endet das meistens damit, dass wir die einfachere Lösung nehmen. Das ist gut.
Genau genommen habe ich diesen länglichen Text hauptsächlich deshalb geschrieben, um mir selbst darüber klar zu werden, was sinnvoll ist und was nicht. Es ist ja nicht so, dass ich das alles vor dem Schreiben schon gewusst hätte. Wie viel von dem, was ich recherchiert, durchdacht und geschrieben hab, tatsächlich bei uns in der Praxis ankommt, wird sich noch zeigen. Aber ab jetzt werden wir an den großen Vicco von Bülow denken, wenn wir dieses unsere Gremium mal wieder dem Loriot-Test unterziehen. Und ich geh jetzt zum Kühlschrank und ess den Joghurt — gerade noch rechtzeitig, bevor er abläuft.
[1] Oder im Falle von Joghurt auch noch problemlos einige Zeit danach. Es heißt nicht umsonst Mindesthaltbarkeitsdatum. Ich persönlich halte Lebensmittelverschwendung und die damit einhergehende völlig unnötige Umweltbelastung für einen Skandal. Ja, auch mir wird mal was schlecht. Aber ich versuche das zu vermeiden. Sooo schwer ist das nicht.
[2] Das Inhaltsverzeichnis kann man sich angucken und sehen, dass sich der Standard hauptsächlich mit der Definition von Phasen beschäftigt. Daneben gibt es noch Schwester-Standards: ISO 24748-2 bis ISO 24748-8, die wiederum auf weitere Standards verweisen. Wer einen Eindruck kriegen möchte kann sich mal das LCM Framework des amerikanischen Bildungsministeriums ansehen.
[3] Achtung, auch hier wird der Begriff von manchen für Marketingzwecke gebraucht und unterscheidet sich dann von dem, was ich hier beschreibe. Zu dem Marketing-Teil hab ich ja schon genug gesagt.
Permalink
> Der Blick über den Tellerrand ist wichtig, aber man muss auch auf den eigenen Teller gucken und die Suppe auslöffeln, die man sich eingebrockt hat.
Herrlich! Danke, Christian.