
Der weise Tim und die Schriftrolle
Es begab sich zu der Zeit, als der weise Tim im Tal der großen Ringe weilte, das man das CERN nannte. Damals arbeitete er daran, seine eigene Erfindung zu perfektionieren und damit die Zauberin VERONICA und ihre magischen Taschenratte zu übertrumpfen. Und so schrieb er neben vielem anderen auch eine Schriftrolle, die als RFC 1630 bekannt werden sollte. Diese Schriftrolle beschrieb alle wahren Namen, mit denen man die Ressourcen im großen weltweiten Netzwerk des weisen Tim ansprechen und ihnen Befehle erteilen konnte.
Dies sind die Ursprünge eines nervigen, kleinen Bugs, den wir vor einiger Zeit gejagt und auch erlegt haben. Und wenngleich sich herausstellte, dass der weise Tim an ebendieser Kreatur gänzlich unschuldig war, so muss man doch feststellen, dass die Komplexität dieser seiner Schriftrolle bis heute immer wieder kleinere und größere Bugs aus den Niederhöllen der 90er heraufbeschwört.
Der Bug
Manche Fehler schreien geradezu danach, dass man sie als Lehrbeispiel heranzieht. Letztens hatten wir einen Bug, der genau von dieser Qualität war. An diesem Bug zeigt sich sehr schön, wie unterschiedliche Probleme sich verketten und dann zu einem Bug führen. Wie so oft, handelt es sich hier nämlich nicht um einen einzelnen Denkfehler oder die Nachlässigkeit eines Einzelnen. Vielmehr ist es so, dass ganz viele Umstände zusammen kommen. Häufig kann man die Zusammenhänge Außenstehenden gar nicht erklären, weil viel zu viele Details der Software eine Rolle spielen. Der Fall hier lässt sich aber ganz gut erklären.
In unserer Anwendung wird eine base64-kodierte Zeichenkette per Query-Parameter an eine ReST-Schnittstelle übergeben. Soweit ziemlich unspektakulär. Query-Parameter sind aber auch wieder kodiert. Nicht alle Zeichen, auch nicht alle, die bei base64 verwendet werden, dürfen einfach so in einen QueryString. Also muss der Client bzw. Sender das entsprechend kodieren und der Server bzw. Empfänger dekodiert es dann wieder. Das ist normalerweise auch kein Problem. Frameworks kümmern sich um diese Details und man hat i.d.R. nicht allzu viel damit zu tun.
Im konkreten Fall haben wir den QueryString doppelt dekodiert. Dadurch gab es dann manche Fälle, in denen die genannte base64-kodierte Zeichenkette kaputt gegangen ist (je nachdem, ob die Zeichenkette zufällig ein „+“ enthielt, was bei base64 vorkommen kann, aber nicht muss.
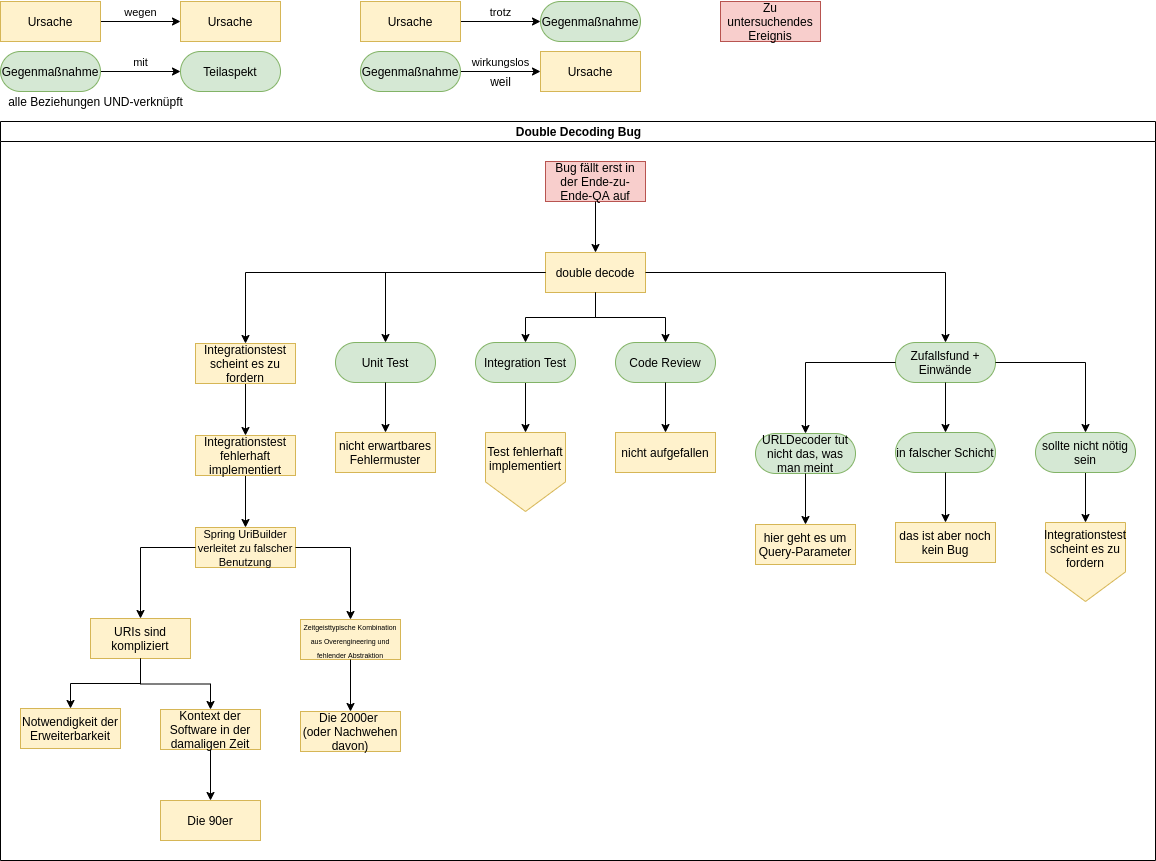
Double Decode — ein klassischer Bug. Aber wie ist er entstanden? Immerhin haben wir diverse Gegenmaßnahmen getroffen, um Bugs zu verhindern.
Die Gegenmaßnahmen
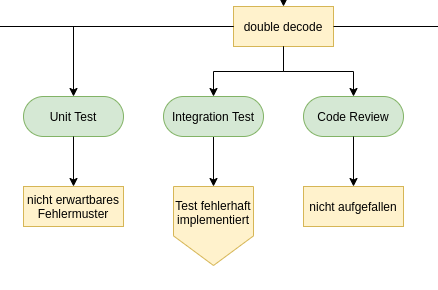
Auch wir können nicht bugfrei coden. Wer könnte das schon von sich behaupten! Deshalb treffen wir die üblichen Gegenmaßnahmen: Unit-Tests, Integrationstests und Codereviews. Damit schaffen wir es, den allergrößten Teil der Bugs zu verhindern bzw. zu bemerken, bevor sie live gehen.
Unit-Tests operieren auf der Ebene von Java-Methoden. Das Dekodieren wird normalerweise vom Framework übernommen, das bei den Unit-Tests nicht aktiv ist. Das genannte Dekodierungsproblem war für den Unit-Test also unsichtbar.
Deshalb schreiben wir Integrationstests. Diese integrieren den Code mit dem Framework, um andere Arten von Fehlern (wie dieses Dekodierungsproblem) zu finden. Blöderweise war der Integrationstest aber fehlerhaft implementiert.
Im Code-Review ist das Problem auch nicht aufgefallen. Wir sind halt auch nur Menschen.
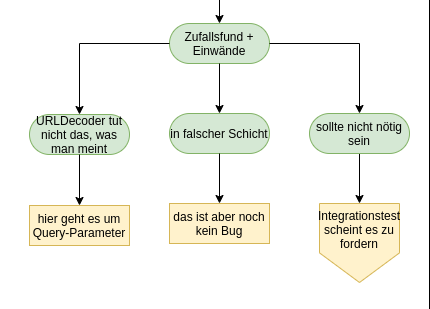
Genau genommen stimmt es nicht ganz, dass der Bug im Code Review nicht aufgefallen ist. Nachdem das eigentliche Code Review durch war, bin ich per Zufall über die fehlerhafte Stelle im Code gestolpert. Irgendwas war da merkwürdig. Mitten im Code war ein Aufruf von URLDecoder.decode(). Das hat mich stutzig gemacht. Warum ist das merkwürdig? Aus mehreren Gründen:
- Wir bauen unsere Software in Schichten auf (oh Wunder!). Die oberste Schicht boundary kümmert sich um ReST. Darunter liegt die control-Schicht, in der die Fachlogik implementiert ist. Der fragliche Methodenaufruf befand sich in der control-Schicht. Dort hatte er ganz sicher nichts verloren. Wenn, dann war das ein Detail der ReST-Schnittstelle. Dass der Parameter mal Teil einer URL war, sollte in dieser Schicht irrelevant sein.
- Selbst, wenn der Aufruf in der Boundary gewesen wäre, wäre das ungewöhnlich gewesen (wenngleich auch weniger auffällig. Vielleicht hätte ich dort das Problem gar nicht erst bemerkt). Eigentlich würde man ja von einem Framework wie Spring Web oder Jersey erwarten, dass sich das Framework um solche Details kümmert. Und Spoiler: Dem ist auch so.
- Zum Dritten ist URLDecoder eine Klasse, die nicht ganz das tut, was man vielleicht vermutet. Eigentlich ist die Klasse falsch benannt. Jedes Mal, wenn ich einen entsprechenden Aufruf sehe, werde ich hellhörig und guck mir genau an, ob das wirklich korrekt verwendet ist.
Ich hab mit dem Kollegen geredet, der den Code geschrieben hat, und auf jeden meiner Einwände wusste er eine gute und überzeugende Antwort. Ja, URLDecoder kann man falsch verwenden. Im speziellen ist es so, dass ‚+‘-Zeichen in einer URL vor und nach dem ‚?‘ (also im QueryString oder im Pfad) unterschiedlich behandelt werden müssen. URLDecoder implementiert den Algorithmus für den QueryString, nicht für den Pfad. Der fragliche Parameter wird aber als Query-Parameter übergeben. Das ist also kein Problem.
Mein zweiter Einwand bezog sich darauf, dass das Decoding in der falschen Schicht passiert. Das ist soweit richtig, aber insgesamt noch kein Bug, sondern nur eine „Unschönheit“. Bei Gelegenheit kann man das ja mal refactorn.
Eigentlich sollte der Aufruf ja gar nicht notwendig sein. Dachte sich mein Kollege auch. Aber der Integrationstest hat gezeigt, dass er doch notwendig war. Nur deshalb hat er ihn eingebaut.
Das hat mich aufs erste überzeugt. Es waren wirklich gute Argumente. Wir haben den Bug also übersehen. Erst die Ende-zu-Ende-QA hat gemerkt, dass unser System nicht in allen Fällen funktioniert. Der Bug ist also nicht live gegangen. Trotzdem: Erst das letzte Sicherheitsnetz hat das Problem endgültig aufgedeckt.
Der fehlerhafte Integrationstest
Fehler passieren. Und hier ist ja noch nicht mal was Wirkliches passiert. Aber es ist trotzdem mal ganz interessant, sich den Bug mal genauer an zu gucken. Wie ist er überhaupt entstanden? Was hat denn zu diesem fehlerhaften Integrationstest geführt, der suggeriert hat, dass man nochmal dekodieren müsste, obwohl das Framework das bereits tut? Schauen wir uns das mal an. So in etwa sah der Test ursprünglich aus:
1 2 3 4 5 6 7 8 9 10 11 | @Test void shouldFooBar() { String value = "foo+"; String bar = "bar"; webTestClient.get() .uri(uriBuilder -> uriBuilder.path("foo/{bar}") .queryParam("name", value) .build(bar)) .exchange() .expectStatus().is2xxSuccessful(); } |
Sieht doch vollkommen normal aus, nicht? So funktioniert der Code aber nicht, weil die Variable value nicht richtig kodiert wird. Konkret wird das enthaltene „+“ nicht kodiert. OK, 2. Versuch:
1 2 3 4 5 6 7 8 9 10 11 | @Test void shouldFooBar() { String value = "foo+"; String bar = "bar"; webTestClient.get() .uri(uriBuilder -> uriBuilder.path("foo/{bar}") .queryParam("name", URLEncoder.encode(value)) // explicit encoding .build(bar)) .exchange() .expectStatus().is2xxSuccessful(); } |
Das URLEncoder.encode() im Test erfordert dann natürlich ein URLDecoder.decode() im Produktivcode. Und so wird der Test auch grün.
Im Test wird jetzt also doppelt kodiert: Einmal explizit via URLEncoder.encode(). Das kümmert sich auch um die +-Zeichen. Dann nochmal vom UriBuilder (was +-Zeichen ignorieren würde). Im Produktivcode wird dann auch zweimal dekodiert: einmal vom Rest-Framework und einmal explizit via URLDecoder.decode(). Der Test wird grün. Der echte Client wird aber natürlich nur einmal encoden.
OK, „dumm gelaufen“, könnte man sagen. Eigentlich könnte man das bei quasi jedem Bug sagen. Aber das bringt uns natürlich nicht weiter. Um wirklich zu verstehen, was der eigentliche Grund für den Bug ist, müssen wir ein wenig in die Mottenkiste greifen.
URIs, URLDecoder und die 90er
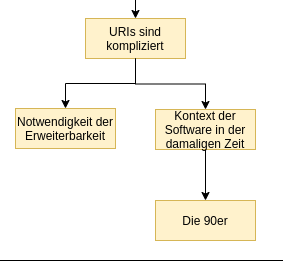
URIs sind kompliziert — deutlich komplizierter, als man das auf den ersten Blick vermuten würde. Wer das nicht glaubt, sollte den Artikel What every web developer must know about URL encoding lesen. Das, was dort beschrieben ist, ist auch wirklich nur ein Teil der Komplexität. Von Punycode, theoretischen und faktischen Längenbegrenzungen, framework-spezifischem Mapping von Arrays auf Query-Parameter, etc. ist ist da noch gar nicht die Rede.
Die Komplexität von URLs liegt nicht daran, dass Tim Berners-Lee blöd war. Im Gegenteil. Ich halte URIs für ein wirklich gut durchdachtes Konzept. Man muss sich vergegenwärtigen, in welcher Zeit sie entstanden sind und was sie leisten. Das Internet von 1994 war gänzlich anders als heute. Das WWW war eine neue Erfindung von der niemand wusste, ob sie sich durchsetzen würde. Dafür gab es Dienste, die heute kaum jemand kennt (Gopher, WAIS, Prospero, …) und andere, die damals einen gänzlich anderen Stellenwert hatten (z.B. FTP).
Unicode gab es zwar schon, aber hatte sich bei weitem noch nicht durch gesetzt. Und selbst wenn man das vorausgesehen hätte: Auch das Unicode von 1994 war ein anderes als heute. UTF-8 sollte erst zwei Jahre später entstehen und sich erst in den Jahren darauf durchsetzen. Deshalb ist die Zeichenkodierung in URIs applikationsspezifisch. Was genau also %B5 ist, ist durch den Standard nicht genau definiert. Damals war das schlicht und einfach notwendig, weil es keine allgemein anerkannte, weit verbreitete Kodierung gab. Man hätte jetzt irgend eine — zum damaligen Zeitpunkt existente — Kodierung festlegen können. Das hätte vielleicht UCS-2 gewesen sein können (ein Vorläufer von UTF-16). Das wäre ein riskanter Schritt gewesen, hätte die damalige Software deutlich komplexer gemacht (weil man damals in den meisten Fällen mit 8bit ASCII und Codepages gearbeitet hat) und wir hätten uns heute darüber aufgeregt, dass eine so antiquierte Kodierung bei URIs nötig ist. Zum damaligen Zeitpunkt war es also vollkommen richtig, die Zeichenkodierung offen zu lassen.
Viel von der Komplexität oder den aus heutiger Sicht „schlechten Entscheidungen“ beim Design von URIs ist also ganz einfach historisch bedingt bzw. dadurch bedingt, dass sich die Welt seit den 90ern weiter gedreht hat.
Der zweite Grund für die Komplexität von URIs ist, dass sie unglaublich flexibel sein mussten. Und sie sind es, denn sie wurden ständig erweitert und sind eine halbe Ewigkeit später immer noch im Einsatz. Mit ihnen sollte man gleichermaßen HTTP-Ressourcen, Dateien auf einem FTP- oder Gopher-Server und E-Mail-Links beschreiben können. Außerdem musste das Konzept auf beliebige weitere, in den 90ern noch vollkommen unbekannte Zwecke nutzbar sein.
Das führt dazu, dass es nicht einen einzelnen RFC für URIs gibt, der alles beschreibt. Vielmehr gibt es eine ganze Reihe von RFCs die Lücken lassen und aufeinander aufbauen. Darüber hinaus gibt es diverse weitere nicht-standardisierte Konventionen, Implementierungsdetails, etc. sodass man leider nicht einfach sagen kann „ich guck mal schnell im RFC nach“, wenn man nach einer definitiven Antwort sucht.
Die URIs aus RFC 1630 sind also nicht ganz das, was wir uns heute darunter vorstellen. So gab es die Unterscheidung zwischen URI, URL und URN tatsächlich damals schon. Dafür war beispielsweise das Format, in dem Query-Parameter übergeben werden, offen gelassen. Es gab nur den QueryString als Ganzes und separate RFCs haben dann für gewisse Fälle (wie HTML-Formulare) weiter spezifiziert, wie der Query-String in Schlüssel-Wert-Paare einzuteilen ist.
Um mal ein weiteres Beispiel für die Flexibilität von URIs, bzw. im speziellen URLs, zu zeigen, gucken wir uns kurz mal das Schema „file“ an. Ich hab mich lange gewundert, warum http-URLs immer einen Doppelslash haben und file-URLs einen Dreifachslash:
1 | file:///path/to/some/file.txt |
Die Hintergründe hab ich erst durch den RFC verstanden. Die generische Syntax einer URL sieht in etwa so aus:
1 2 3 4 5 6 7 8 9 10 11 | https://hans:geheim@www.example.com:8080/pathsegment/index.html?p1=A&p2=B#ressource \___/ \__/ \____/ \_____________/ \__/\_____________________/ \_______/ \_______/ | | | | | | | | Schema | Password Host Port Path Query Fragment User \_________/ | Credentials \______________________________/ | Authority |
Jeder dieser Bestandteile ist durch ein Trennzeichen vom Rest getrennt:
- Schema — dann „:“
- „//“ dann Authority
- Credentials — dann „@“
- „:“ — dann Password
- Host
- „:“ — dann Port
- „/“ — dann Path
- „?“ — dann Query
- „#“ — dann Fragment
Auf den ersten Blick sieht das ein wenig krumm aus. Mal gehört das Trennzeichen zum vorherigen Teil, mal zum darauf folgenden. Letzten Endes ermöglicht die Syntax aber, dass man flexibel einzelne Teile der URL weglassen kann, wenn sie im konkreten Kontext nicht von Bedeutung sind. So klärt sich aus das Rätsel mit den file-URLs:
file://some-host/some-path/filedefiniert eine nicht-lokale Dateifile://localhost/some-path/filedefiniert eine lokale Dateifile:///some-path/filemit implizitem „localhost“file:/some-path/filemit impliziter Authority
Ebenso ist es möglich, relative URLs anzugeben, die bestimmte Informationen weglassen:
http://example.com:8080/path?query#fragmentohne credentialshttp://example.com/path?query#fragmentohne porthttp://example.com/path#fragmentohne query//example.com/path#fragmentohne schema- …
Die Tatsache, dass die Trennzeichen unterschiedlich sind, ermöglicht es also, direkt zu sehen, welche Teile der URL angegeben sind und welche nicht. Das hat aber zur Folge, dass diese Trennzeichen in manchen Teilen der URL kodiert werden müssen (weil sie als Trennzeichen interpretiert würden) und in anderen nicht. Ein „?“ kann im Pfad nicht auftauchen (weil es den Pfad beendet). In Query und Fragment ist es aber ein reguläres Zeichen. Ein „/“ im Pfad definiert eine Hierarchisierung — ein „/“ in Query oder Fragment nicht notwendigerweise. Ein „&“ im Query-String ist ein reserviertes Zeichen mit Spezialbedeutung (auch, wenn die Ausgestaltung der Spezialbedeutung nicht im selben RFC steht) und muss demnach besonders kodiert werden, wenn man wirklich das Zeichen „&“ repräsentieren will. Im Pfad ist das aber ein ganz normales Zeichen und muss nicht kodiert werden.
Diese Komplexität kommt aus der Flexibilität, die URLs und URIs nunmal haben sollen. Dazu gibt es noch eine weitere Verkomplizierung: Für das Kodieren von Leerzeichen in Query-Strings gibt es nämlich eine historisch bedingte Sonderregel:
Within the query string, the plus sign is reserved as shorthand notation for a space. Therefore, real plus signs must be encoded. This method was used to make query URIs easier to pass in systems which did not allow spaces.
Oder anders ausgedrückt: Vor dem ? kodiert man Leerzeichen als %20, nach dem ? als +. Dafür kodiert man + vor dem ? gar nicht und nach dem ? als %2B. Offensichtlich gab es in den 90ern einen besonderen UseCase, der durch diese Regel vereinfacht wurde. Ich hoffe, dieser UseCase war es wert! Diese Sonderregel hat nämlich schon unzählige Bugs auf dem Gewissen.
Ich hab nicht versucht, mir zu überlegen, wie ich das Problem gelöst hätte, wenn ich in den 90ern die Syntax für URIs zu definieren hätte oder wenn ich heute damit auf der grünen Wiese anfangen würde. Das wäre sowieso nicht mehr als eine theoretische Überlegung aus der nichts folgt (wobei das durchaus interessant sein könnte… hm…). Fakt ist jedenfalls, dass die Syntax, so wie sie ist, besteht und dass sie ihre Gründe hat.
Die Klasse URLEncoder bildet diese Komplexität tatsächlich nur unzureichend ab. Sie implementiert das Percent-Encoding für Query-Strings mit der genannten Sonderregel für Leerzeichen. Für alles andere ist die Klasse nicht zu gebrauchen und um die innere Syntax von Query-Strings (i.d.R. application/x-www-form-urlencoded) muss man sich selbst kümmern.
UriBuilder und diese verdammten 2000er
URLEncoder ist also nicht der Weisheit letzter Schluss. Man bräuchte etwas, das einem den ganzen Kodierungswahnsinn von der Backe hält: einen Uri…Builder. So etwas ist dann auch entstanden. Allerdings hatte sich die Welt in der Zwischenzeit weiter gedreht.
Die 90er, die Zeit den Aufbruchs und der Pioniere war vorbei. Mittlerweile befinden wir uns in den 2000ern. Die Dotcom-Blase war geplatzt, das iPhone kam auf den Markt. Die große Zeit der Webforen brach an und ging mit dem Aufstieg der sozialen Netzwerke wieder zu Ende. Kurz: Auch das ist noch eine Zeit mit viel Wandel. Allerdings eine, die in der Softwareentwicklung mit einem ganz bestimmten Zeitgeist verknüpft ist. Die 2000er waren die Zeit von XML, MDA und SOAP, eine Zeit in der ESBs verkauft wurden und in der man alles in Konfigurationsdateien gepackt hat, was nicht bei drei auf den Bäumen war. Man wollte es diesmal einfach richtig machen. Und man wollte es so sehr, dass das gehörig nach hinten losging. Ich verbinde die 2000er mit unnötiger Komplexität, zum Teil mit fehlender oder falscher Abstraktion und generell mit „gut gemeint“ und weniger mit „gut gemacht“.
Man kann das natürlich nicht als harte Grenzen ansehen. William Gibson hat mal treffender Weise gesagt „Die Zukunft ist schon da — sie ist nur nicht gleich verteilt.“ In manchen Ecken der Softwareentwicklung steckte man 2005 noch tief in den 90ern und an anderer Stelle hatte man womöglich schon die 2000er innerlich überwunden. So ist das halt mit der Zukunft.
Die Anfänge von JaxRS liegen im Jahr 2007. Das war so eine Ecke, in der man die 2000er bereits überwunden hatte. Der UriBuilder aus JaxRS ist auch tatsächlich wirklich gut. Wenn man den UriBuilder verwendet, muss man sich mit den ganzen ekligen Details nicht auseinander setzen. Das sieht dann in etwa so aus:
1 2 3 4 5 6 | URI uri = UriBuilder.fromUri("https://example.com/") .segment("authors") .segment("Terry Pratchett") .segment("books") .queryParam("containingCharacters", "Ponder Stibbons + Rincewind") .build(); |
1 | https://example.com/authors/Terry%20Pratchett/books?containingCharacters=Ponder+Stibbons+%2B+Rincewind |
Natürlich hat auch Spring ein Äquivalent — den UriComponentsBuilder. Auf den ersten Blick sieht der fast genauso aus. Allerdings: Auch wenn der UriComponentsBuilder zeitlich nach dem UriBuilder entstanden ist, waren dort die 2000er offensichtlich noch nicht vorbei. Und das war der eigentliche Grund für unseren Bug.
Der UriBuilder von JaxRS hat eine klare Abstraktion. Das Ding baut valide URIs und nur valide URIs. Man kann Pfadsegmente übergeben und Query-Parameter, etc. Und man muss nicht steuern, was wie kodiert wird. Genau genommen kann man auch kaum steuern, was wie kodiert wird. Der UriComponentsBuilder ist da anders. In den 2000ern (die auch 2011 bei Spring noch nicht ganz vorbei waren), wollte man alles steuern und konfigurieren können. Man wollte Kontrolle haben und hat dafür furchtbar gerne abstrakte Klassen, Strategy-Patterns und Factories eingesetzt. Dafür hat man vergessen, dass eine Klasse ein klares Konzept kapseln sollte. Selbstverständlich auch hier.
Folgendes ist unser erster Versuch:
1 2 3 4 5 6 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("Terry Pratchett") .pathSegment("books") .queryParam("containingCharacters", "Ponder Stibbons + Rincewind") .build(); |
Sieht fast genauso aus wie bei JaxRS. So würde das doch jeder machen. Oder nicht? Was kommt raus?
1 | https://example.com/authors/Terry Pratchett/books?containingCharacters=Ponder Stibbons + Rincewind |
Ja, das bedeutet, das Resultat ist nicht kodiert und damit nicht RFC-konform. Ernsthaft. Ich konnte es auch erst nicht glauben, aber der Builder baut tatsächlich invalide URIs. Aber wie gesagt: Man hat ja jetzt mehr Kontrolle über die Kodierung. Da muss sich doch etwas finden… Mal versuchen: Welche der folgenden Codesnippets ist korrekt?
1 2 3 4 5 6 7 8 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("Terry Pratchett") .pathSegment("books") .queryParam("containingCharacters", "Ponder Stibbons + Rincewind") .encode() .build() .toUri(); |
1 2 3 4 5 6 7 8 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("Terry Pratchett") .pathSegment("books") .queryParam("containingCharacters", "Ponder Stibbons + Rincewind") .build() .encode() .toUri(); |
1 2 3 4 5 6 7 8 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("Terry Pratchett") .pathSegment("books") .queryParam("containingCharacters", "Ponder Stibbons + Rincewind") .encode() .build(/*encoded=*/ false) .toUri(); |
1 2 3 4 5 6 7 8 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("Terry Pratchett") .pathSegment("books") .queryParam("containingCharacters", "Ponder Stibbons + Rincewind") .build(/*encoded=*/ false) .encode() .toUri(); |
Und was sind die Unterschiede? Verwirrend. OK, lesen wir mal in der Doku nach:
- UriComponentsBuilder#encode(): Pre-encodes the URI template first and then strictly encodes URI variables when expanded.
- UriComponents#encode(): Encodes URI components after URI variables are expanded.
Both options replace non-ASCII and illegal characters with escaped octets. However, the first option also replaces characters with reserved meaning that appear in URI variables.
[…]
For most cases, the first option is likely to give the expected result, because it treats URI variables as opaque data to be fully encoded, while option 2 is useful only if URI variables intentionally contain reserved characters.
OK, es gibt also ein „pre-encoding“ und ein „strict encoding“. Und zwei Varianten die fast gleich aussehen, von denen die eine aber wahrscheinlich nicht das ist, was man will. Aber so furchtbar viel schlauer sind wir noch nicht. Aber das alles spielt eigentlich keine Rolle, denn keine einzige der obigen Varianten liefert ein korrekt kodiertes Ergebnis. Diesmal zwar valide URLs, aber halt falsch kodiert.
Vielleicht hilft ja die DefaultUriBuilderFactory, die weiter unten in der Doku erwähnt wird. Da kann man dann einen EncodingMode setzen:
- TEMPLATE_AND_VALUES: Uses UriComponentsBuilder#encode(), corresponding to the first option in the earlier list, to pre-encode the URI template and strictly encode URI variables when expanded.
- VALUES_ONLY: Does not encode the URI template and, instead, applies strict encoding to URI variables through UriUtils#encodeUriUriVariables prior to expanding them into the template.
- URI_COMPONENT: Uses UriComponents#encode(), corresponding to the second option in the earlier list, to encode URI component value after URI variables are expanded.
- NONE: No encoding is applied.
Wir könnten uns jetzt hinsetzen und uns überlegen, was die Unterschiede sind und welche UseCases diesen Irrsinn an Patternhölle und Komplexität rechtfertigen. Aber Spoiler: Diese Varianten sind noch falscher, also interessieren sie uns nicht. Korrekt wäre so:
1 2 3 4 5 6 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("{author}") .pathSegment("books") .queryParam("containingCharacters", "{character}") .build("Terry Pratchett", "Ponder Stibbons + Rincewind") |
oder, wenn man es etwas komplizierter haben möchte, so:
1 2 3 4 5 6 7 | URI uri = UriComponentsBuilder.fromUriString("https://example.com/") .pathSegment("authors") .pathSegment("{author}") .pathSegment("books") .queryParam("containingCharacters", "{characters}") .buildAndExpand("Terry Pratchett", "Ponder Stibbons + Rincewind") .toUri(); |
Wobei natürlich anzumerken ist, dass buildAndExpand(), anders als der Name suggeriert, nicht mehr macht als build(), sondern weniger. Also… weniger als manche Überladungen von build(). Aber lassen wir das. Meine Tischkante hat schon genug Bissspuren.
Mit dem Wissen um die korrekte Verwendung der Klasse können wir jetzt endlich unseren Integrationstest fixen:
1 2 3 4 5 6 7 8 9 10 11 | @Test void shouldFooBar() { String value = "foo+"; String bar = "bar"; webTestClient.get() .uri(uriBuilder -> uriBuilder.path("foo/{bar}") .queryParam("name", "{value}") .build(bar, value)) .exchange() .expectStatus().is2xxSuccessful(); } |
Was lernen wir daraus?
Die eigentliche Ursache für unseren Bug liegt zum einen in der Komplexität der URLs, die durch die Notwendigkeit der Erweiterbarkeit, sowie den historischen Kontext der 90er bedingt ist. Und zum anderen liegt der Grund in Overengineering und fehlender Abstraktion im UriComponentsBuilder und damit um Zeitgeist der 2000er.
Ich bin mir sicher, mit der ganzen Komplexität im UriComponentsBuilder und der DefaultUriBuilderFactory kann man bestimmt auch obskure Randfälle ganz besonders toll lösen. Aber wen kümmert das, wenn die 99% Normalfälle so schwer richtig zu machen sind. Die Klasse ist jedenfalls nicht Easy to Use and Hard to Misuse.
Als Daumenregel werde ich mir merken, dass die Methode queryParam() niemals mit einer Variable als zweiten Parameter aufgerufen werden sollte (queryParam("key", value)), sondern immer ein String-Literal mit einer Template-Variablen (queryParam("key", "{value}")) oder von mir aus mit einem String-Literal bei dem klar ist, dass keine Kodierung notwendig ist (queryParam("key", "value")).
Ich weiß nicht, ob man das merkt, aber ich bin kein Fan von UriComponentsBuilder. Aber immerhin eines hat die Klasse geschafft: Sie gibt ein ziemlich gutes schlechtes Beispiel ab. Ob der weise Tim sich das wohl erträumt hatte? Damals im Tal der großen Ringe als er seine berühmte Schriftrolle schrieb?