Die Präsidentenmacherin und der Timeout
„Christian, we want you for president!“ Steffi, die Abteilungsleiterin der Betriebs-Kollegen steht in der Tür und bedeutet mir mitzukommen. So bin ich auch noch nicht begrüßt worden, denke ich mir […]

„Christian, we want you for president!“ Steffi, die Abteilungsleiterin der Betriebs-Kollegen steht in der Tür und bedeutet mir mitzukommen. So bin ich auch noch nicht begrüßt worden, denke ich mir […]
Allgemein Ich sollte mehr bloggen. Hier mal eine Kurzzusammenfassung von einigem, über das ich hätte bloggen können, wenn ich es denn getan hätte. Softwareentwicklung Coding the Architecture ist ein schönes […]
Gerade gehört: SoftwareArchitekTOUR: Patterns in der Java-Welt. Vor einiger Zeit hab ich die ersten beiden Episoden gehört. Jetzt hab ich mir mal diese angetan. Und natürlich kann ich mich gewisser […]
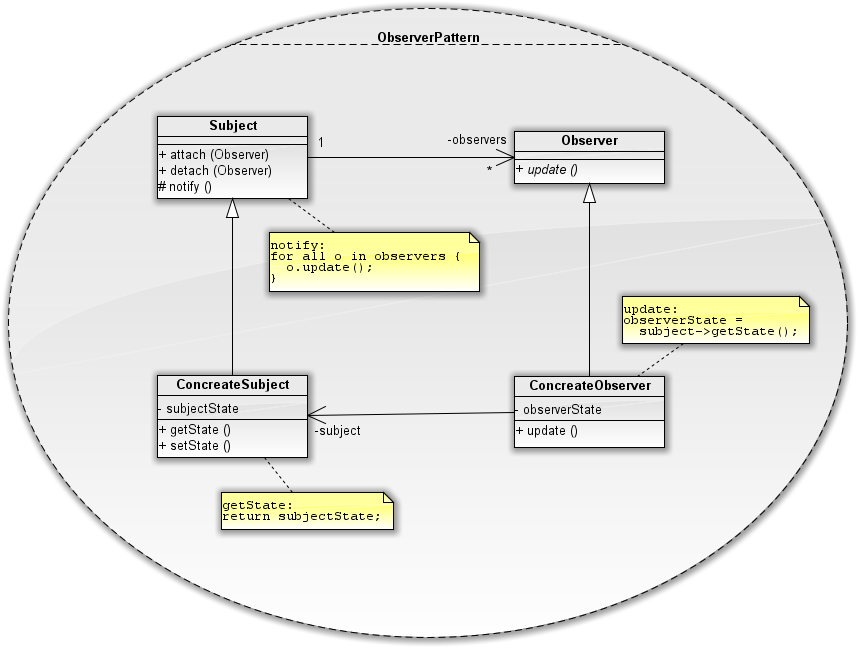
Überblick Motivation Es soll vorkommen, dass man in der Softwareentwicklung Probleme lösen muss. Und es soll vorkommen, dass man ein Problem, dass man schonmal gelöst hatte, nochmal lösen muss. Und […]
Jeder, der schon eine Weile programmiert, wird die Situation kennen: Man liest Code (entweder fremden oder eigenen) und es läuft einem kalt den Rücken runter, die Zehnägel stellen sich auf […]
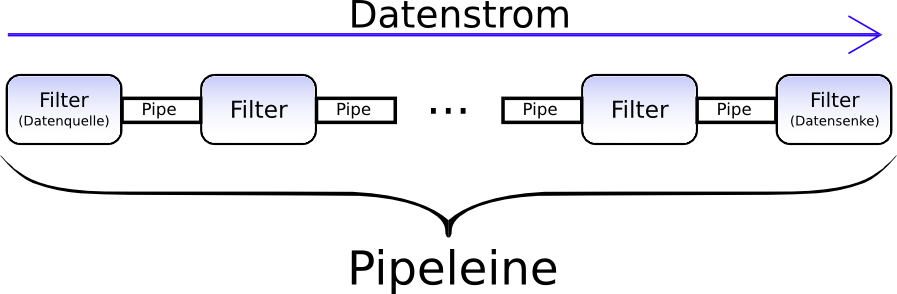
Über „Pipe-and-Filter“ wollte ich eigentlich schon ne ganze Zeit lang was schreiben. Bei meinem Vortrag auf den Delphi-Tagen hab ich das Pattern auch wieder erwähnt und so will ich jetzt […]
Im letzten Semester habe ich eine Seminararbeit zum Thema „Software Architectural Tactics and Patterns for Safety and Security“ geschrieben. Grob gesagt geht es darum, wie man auf Architektur-Ebene Sicherheitsaspekte (Safety […]
Vor einiger Zeit hab ich mal Multimethoden vorgestellt. Dabei hab ich auch angedeutet, dass man Multiple Dispatch über das Visitor-Pattern simulieren kann. Das hab ich jetzt mal selbst gebraucht. Da […]
Nachdem in letztens ja gegen Singletons gewettert habe, habe ich nun selbst mal eines implementiert. Wie im verlinkten Artikel erläutert, gibt es ein paar reale Einsatzszenarien, in denen sie wirklich […]
In letzter Zeit hab ich mich ein bisschen mit Design Patterns beschäftigt. Dabei bin ich auch auf das Interpreter-Pattern gestoßen. Und da ich Parser ebenfalls interessant finde und eh mal […]