Wie man Software entwirft
Wie schreibt man eigentlich Software? – Nun, man tippt einfach den Code. Und wie weiß man welchen Code man schreiben muss? – Äh… – Also, wenn man plangetrieben entwickelt, hat […]

Wie schreibt man eigentlich Software? – Nun, man tippt einfach den Code. Und wie weiß man welchen Code man schreiben muss? – Äh… – Also, wenn man plangetrieben entwickelt, hat […]
Joshua Bloch hatte vermutlich schon die ein oder andere schlechte Idee. Wahrscheinlich sogar ein paar richtig bescheuerte Ideen. Und genau deshalb hat er Ahnung. In der Java API stecken ne […]
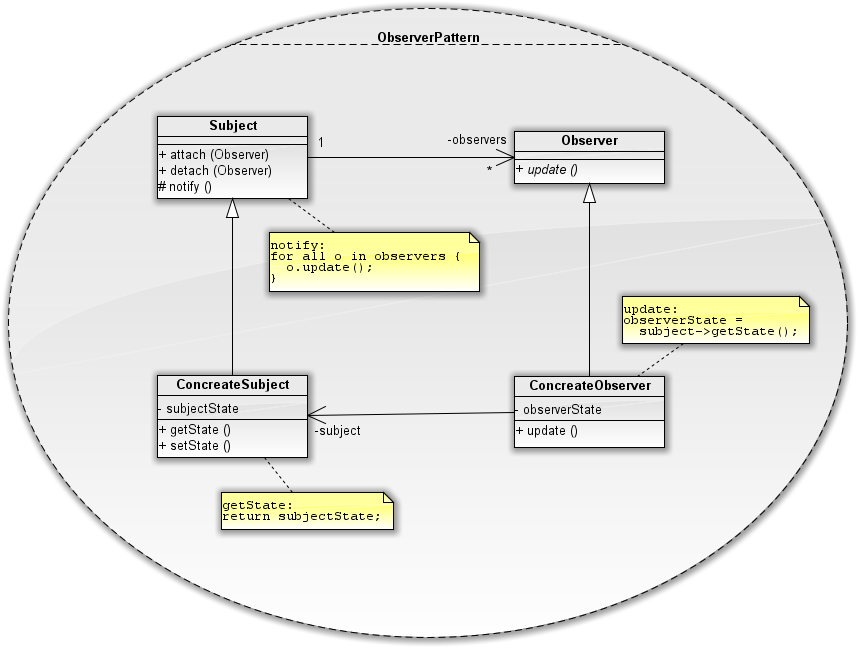
Überblick Motivation Es soll vorkommen, dass man in der Softwareentwicklung Probleme lösen muss. Und es soll vorkommen, dass man ein Problem, dass man schonmal gelöst hatte, nochmal lösen muss. Und […]
Ich hatte ja schon angekündigt, dass ich mein Versprechen auf den letzten Delphi-Tagen in Raten erfüllen werde. Immer mal wieder landet etwas zu den Softwareentwicklungs-„Daumenregeln“ oder -Prinzipien hier im Blog. […]
Informatik – Im Weitesten Sinne Martin Fowler über Zertifikate Nochmal Martin Fowler. Diesmal über die Umsetzung von Rollen. Fowler zeigt hier, wie man auf verschiedene Art und Weise Rollen umsetzen […]
Wie ich schon mehrfach erläutert habe, sehe ich Softwareentwicklung als das ständige Ausbalancieren von Prinzipien oder „Daumenregeln“. Es gibt eine ganze Menge solcher Daumenregeln (ich hab mal an die hundert […]
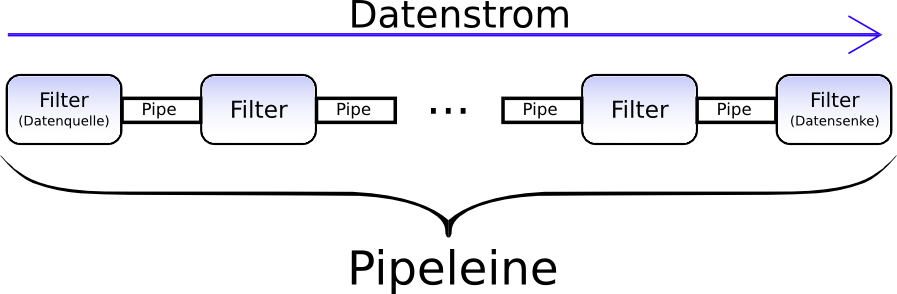
Über „Pipe-and-Filter“ wollte ich eigentlich schon ne ganze Zeit lang was schreiben. Bei meinem Vortrag auf den Delphi-Tagen hab ich das Pattern auch wieder erwähnt und so will ich jetzt […]
oder: Wie man objektorientiert denkt Abstract Zielgruppe: OOP-Einsteiger und -Fortgeschrittene, sowie alle, die das Gefühl haben, die OOP noch nicht ganz verstanden zu haben. Ein OOP-Tutorial sollte man aber zumindest […]
Ich bin gerade dabei, meine Folien für die Delphi-Tage zu machen. Wie schon mehrmals erwähnt geht es um objektorientiertes Denken. In diversen Diskussionen in den Foren habe ich gemerkt, dass […]
In letzter Zeit hab ich mich ein bisschen mit Design Patterns beschäftigt. Dabei bin ich auch auf das Interpreter-Pattern gestoßen. Und da ich Parser ebenfalls interessant finde und eh mal […]