Seid stolz auf eure Fehler
Ja wirklich. Aber ich fürchte, das muss ich erklären. Wir lernen meines Erachtens hauptsächlich aus Fehlern. Entweder aus eigenen oder aus denen von anderen. Deshalb sage ich meinen Studenten immer, […]

Ja wirklich. Aber ich fürchte, das muss ich erklären. Wir lernen meines Erachtens hauptsächlich aus Fehlern. Entweder aus eigenen oder aus denen von anderen. Deshalb sage ich meinen Studenten immer, […]
Letztens hab ich als kleine Seminararbeit in der Uni was über Continuous Integration geschrieben. Hier meine Seminararbeit: Und hier die zugehörige Präsentation: Wer sich für CI interessiertn sollte aber vielleicht […]
Im ersten Semester lernt man im Informatikstudium Restklassenringe kennen. Diese bilden die mathematische Basis für diverse Kryptographie (beispielsweise RSA), aber auch anderes Zeug wie CRC. Gestern hatte ich im Forum […]
Der FIT hat in diesem Jahr neben den schon mehrmals angebotenen — und im übrigen ebenfalls empfehlenswerten — Firmenexkursionen auch eine Veranstaltung zum Thema Agile Softwareentwicklung angeboten: Summerschool „Agile Software […]
Wenn man studiert, hat man üblicherweise Lehrveranstaltungen. Und zumindest in der Informatik ist es auch üblich, da wirklich hinzugehen [1]. Und es ist üblich, dass es die Folien zum Download […]
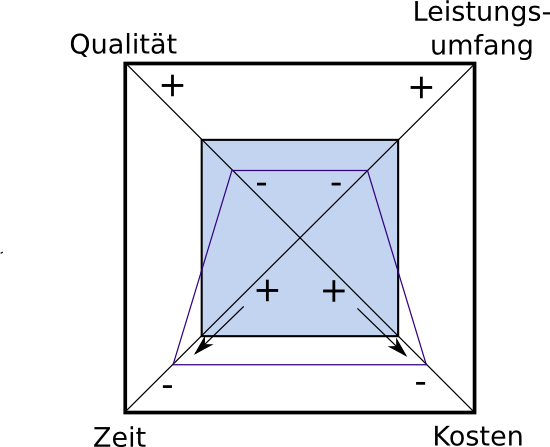
In der Vorlesung Projektmanagement hört man folgendes: Die Produktivität eines Softwareentwicklungsteams ist konstant. Will man mehr leisten, in kürzerer Zeit leisten, zu geringeren Kosten leisten oder in höherer Qualität leisten, […]
Terminierungsbeweise sind generell unmöglich. Im speziellen sind sie aber meist recht trivial und unter anderem müssen das alle SE1-Studenten mal machen. Das Schema hatte ich schon an die Tafel geschrieben […]
Wöchentlich stelle ich „meinen“ SE1-Studenten ein paar kleine meist sehr einfache Aufgaben. Letztens hab ich ihnen versprochen, die Aufgabe zu „Java“ wird ein Kinderspiel. Und genau das war sie auch: […]
Ich hatte ja noch versprochen die Aufgaben zur Parameterinduktion online zu stellen. Hier sind sie: 12add x 0 = x add x y = 1 + add x (y-1) Behauptung: […]
Das Sortieren ist ein typisches Problem der Informatik. So typisch, dass es mittlerweile dermaßen gut erforscht ist, dass es schon seit mindestens zwei halben Ewigkeiten eine Reihe von Sortieralgorithmen gibt, […]