Von Zielarchitekturen und Polarsternen
Auf der Arbeit kümmere ich mich gerade um die Zielarchitektur für unsere Abteilung. Deshalb hab ich mir mal ganz allgemein Gedanken darüber gemacht, was das eigentlich heißt. Man könnte jetzt […]

Auf der Arbeit kümmere ich mich gerade um die Zielarchitektur für unsere Abteilung. Deshalb hab ich mir mal ganz allgemein Gedanken darüber gemacht, was das eigentlich heißt. Man könnte jetzt […]
Wenn man meine Oma fragt, was ich arbeite, dann würde sie vielleicht sowas sagen wie „irgendwas mit Computer“. Aber, was bin ich denn nun eigentlich? Für manche bin ich vielleicht […]

Design Types Als Entwickler streiten wir uns manchmal, was die beste Lösung ist. Das bleibt nicht aus und genau genommen ist streiten bis zu einem gewissen Grad einfach unser Job. […]
Es war einmal ein König, der hatte drei Kinder und ein kleines, einstmals schönes Schloss. Das Schloss war alt und heruntergekommen und es war dort kalt und feucht. Der König […]
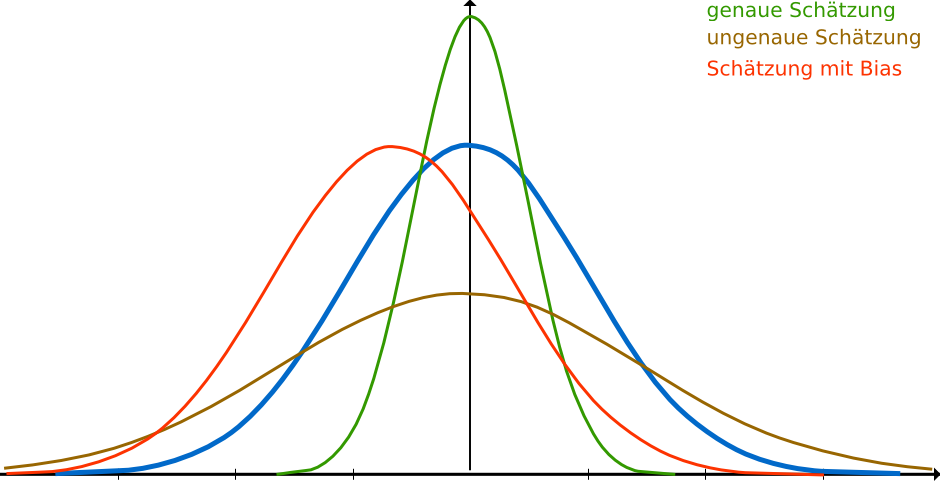
Vor einiger Zeit hat man mir mal gesagt, wenn es um Aufwandsschätzungen geht, schätze ich „konservativ“. Will heißen: Ich schätze übervorsichtig, also zu hoch. Ob das stimmt? Ich weiß es […]

Hänsel und Gretel haben ein spontanes Meeting im Wald. Äh… das heißt… sie haben sich verirrt. Diese Tatsache ist nicht weg zu diskutieren. Hier ist Wald, dort ist Wald. Hier […]
Ich weiß schon, warum ich Entwickler geworden bin. Im Studium hatte ich eine Vorlesung zu „Unternehmensführung“. Strategie, Organisation, Controlling, Personalwirtschaft, internationales Management… alles das hat man mir beigebracht. In der […]
Von manchen Dingen gibt es einfach nur endlich viele. Von Pronomen beispielsweise. Ich, du, er, sie, es, wir, ihr, sie. Das sind die Personalpronomen. Gut, man kann diese noch deklinieren, […]
In den letzten Jahren ist REST zu einer beliebten Schnittstellentechnologie geworden. Das hat mehrere Gründe und einer davon ist, dass REST als einfache Technologie verstanden wird. Und das ist auch […]
Irgendwie komme ich kaum zu posten. Unter anderen wartet ein Artikel zu REST (wobei das vermutlich mehrere werden) in der Pipeline. Jetzt sind aber erstmal die Delphi-Tage dran. Und bevor […]